Содержание
Алгоритм приготовления бутерброда по информатике
Главная » Разное » Алгоритм приготовления бутерброда по информатике
Методическая разработка по информатике и икт (5 класс) по теме: Алгоритмы. Урок 1.
Алгоритмы. Малышева М.И.
Этапы решения задач на ЭВМ
- Постановка задачи
- Построение математической (формализованной) модели.
- выделить существенные признаки объекта;
- определить, что считать аргументами (исходными данными) и результатами;
- определение метода решения (математические соотношения, связывающие результаты с исходными данными)
- Построение алгоритма.
- Программа на языке программирования
- Ввод программы в компьютер, ее тестирование, отладка и выполнение на ЭВМ.
- Анализ результатов. Если необходимо, уточнение модели (перейти к п.2)
Исполнитель и его характеристики
ИСПОЛНИТЕЛЬ — человек или механическое устройство (или, например, компьютер), который умеет выполнять строго определенный набор команд (и больше ничего!).
Среда
СКИ
Набор команд, который умеет выполнять Исполнитель (т.е. список всех команд), называется СИСТЕМОЙ КОМАНД ИСПОЛНИТЕЛЯ (СКИ).Существует множество различных исполнителей. Для знакомства с любым исполнителем, нужно узнать, в какой среде работает исполнитель, и познакомиться с его СКИ (системой команд исполнителя), т.е. узнать:
Задание 1: Назвать исполнителей следующих видов работы: уборка мусора во дворе, перевозка пассажиров, выдача заработной платы, прием экзаменов, сдача экзаменов, обучение детей в школе. Сформулируйте СКИ для каждого из этих исполнителей.
АЛГОРИТМ И ЕГО СВОЙСТВА
АЛГОРИТМ – понятное и точное предписание исполнителю выполнить конечную последовательность команд, приводящую от исходных данных к искомому результату.
Примеры:
- “Пойди туда — не знаю куда, принеси то — не знаю что” (алгоритмом не является)
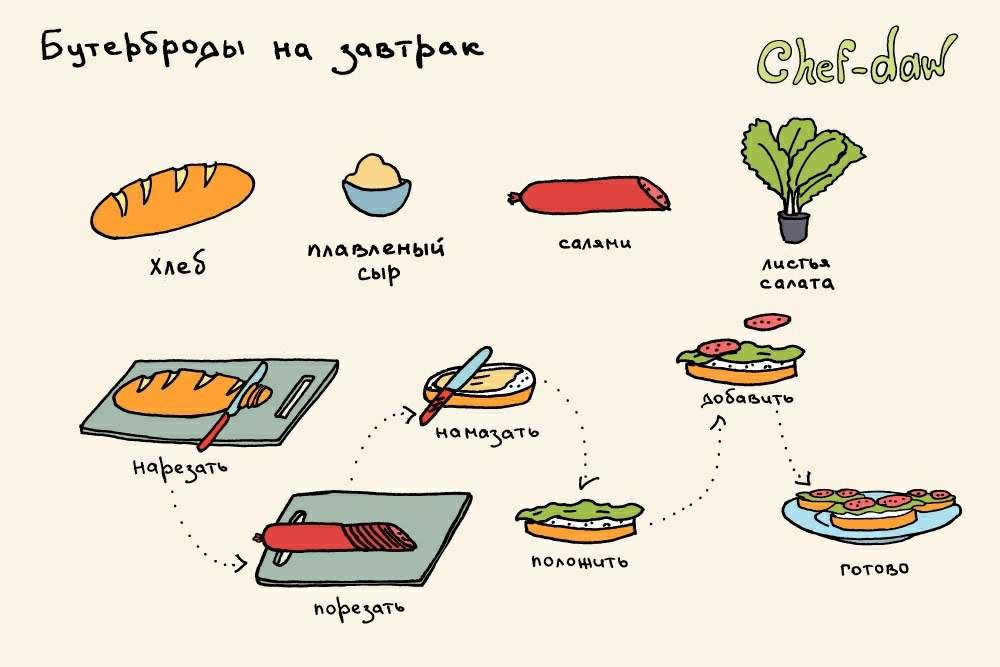
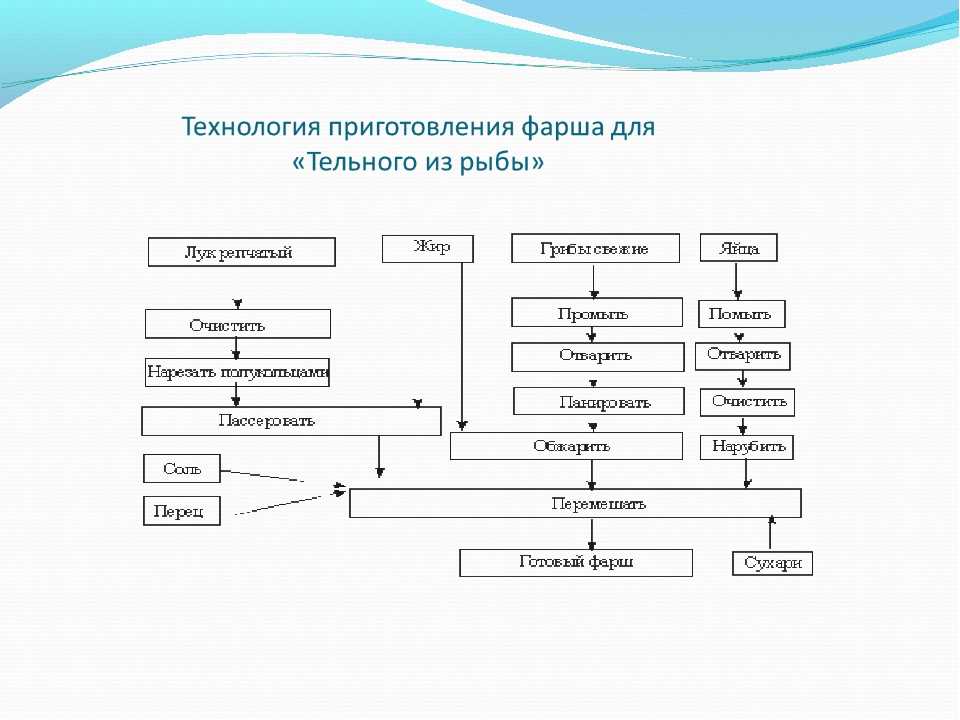
- Алгоритм приготовления бутерброда: исх. данные: хлеб, продукт.
 Искомый результат — бутерброд (ломтик продукта, положенный на ломтик хлеба). Словесный алгоритм: а) отрезать ломтик хлеба; б) отрезать ломтик продукта; в) положить продукт на хлеб.
Искомый результат — бутерброд (ломтик продукта, положенный на ломтик хлеба). Словесный алгоритм: а) отрезать ломтик хлеба; б) отрезать ломтик продукта; в) положить продукт на хлеб.
 Искомый результат — бутерброд (ломтик продукта, положенный на ломтик хлеба). Словесный алгоритм: а) отрезать ломтик хлеба; б) отрезать ломтик продукта; в) положить продукт на хлеб.
Искомый результат — бутерброд (ломтик продукта, положенный на ломтик хлеба). Словесный алгоритм: а) отрезать ломтик хлеба; б) отрезать ломтик продукта; в) положить продукт на хлеб.СВОЙСТВА АЛГОРИТМА:
- ОПРЕДЕЛЕННОСТЬ — предписания в алгоритме должны быть однозначными по смыслу, чтобы исполнитель не принимал самостоятельных решений.
- МАССОВОСТЬ — пригодность для решения целого класса задач данного типа при различных исходных данных, отвечающих общей постановке задачи.
- ДИСКРЕТНОСТЬ — расчлененность алгоритма на отдельные элементарные (дискретные) шаги, которые исполнитель может выполнить без дополнительных разъяснений.
- РЕЗУЛЬТАТИВНОСТЬ — возможность получения результата за конечное число шагов (как бы долго алгоритм ни выполнялся, он все равно когда-нибудь закончится).
- ПОНЯТНОСТЬ – алгоритм должен быть составлен только из команд, входящих в систему команд исполнителя.
Задание 2: Подумайте и напишите, что из ниже перечисленного является алгоритмом, а что нет:
- правила игры в футбол;
- политическая карта мира;
- телефонный справочник;
- вычисление корней квадратного уравнения;
- приготовление завтрака.
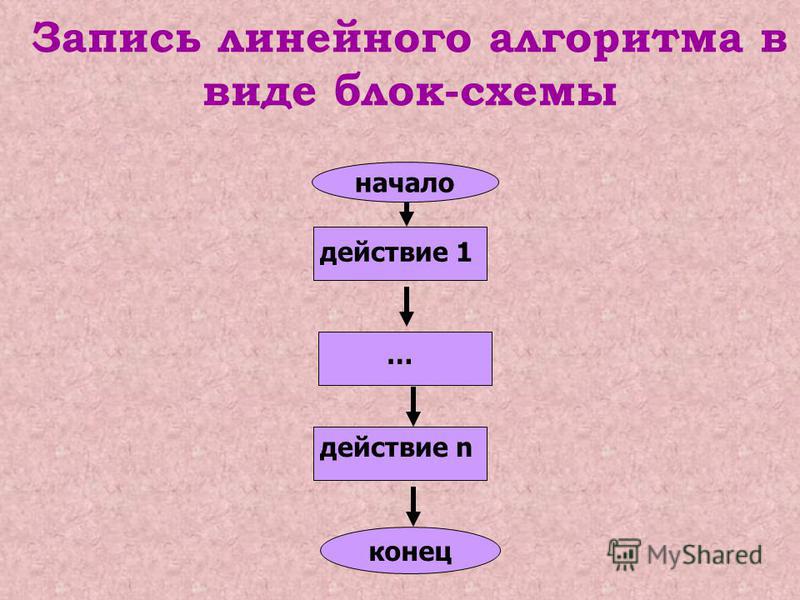
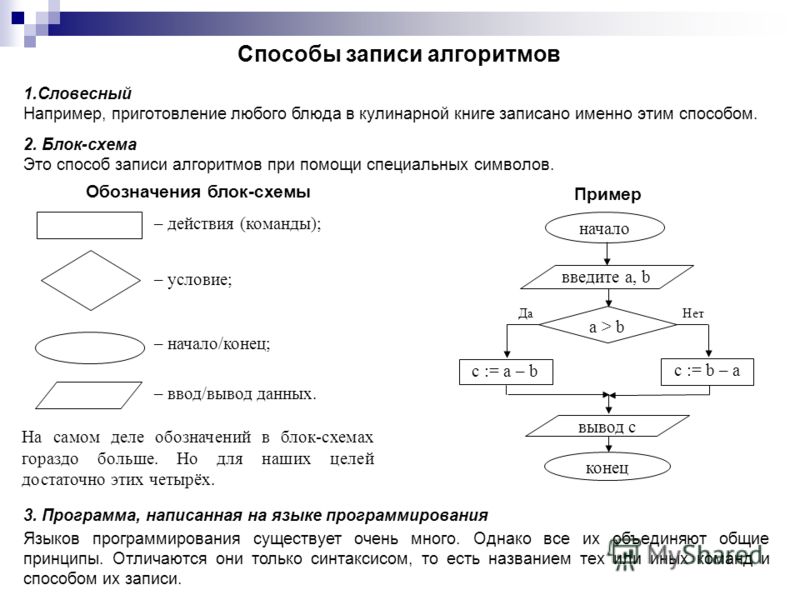
СПОСОБЫ ПРЕДСТАВЛЕНИЯ АЛГОРИТМОВ:
- Словесный (например, алгоритм приготовления бутерброда).
- Графический (в виде блок-схем).
- На алгоритмическом языке.
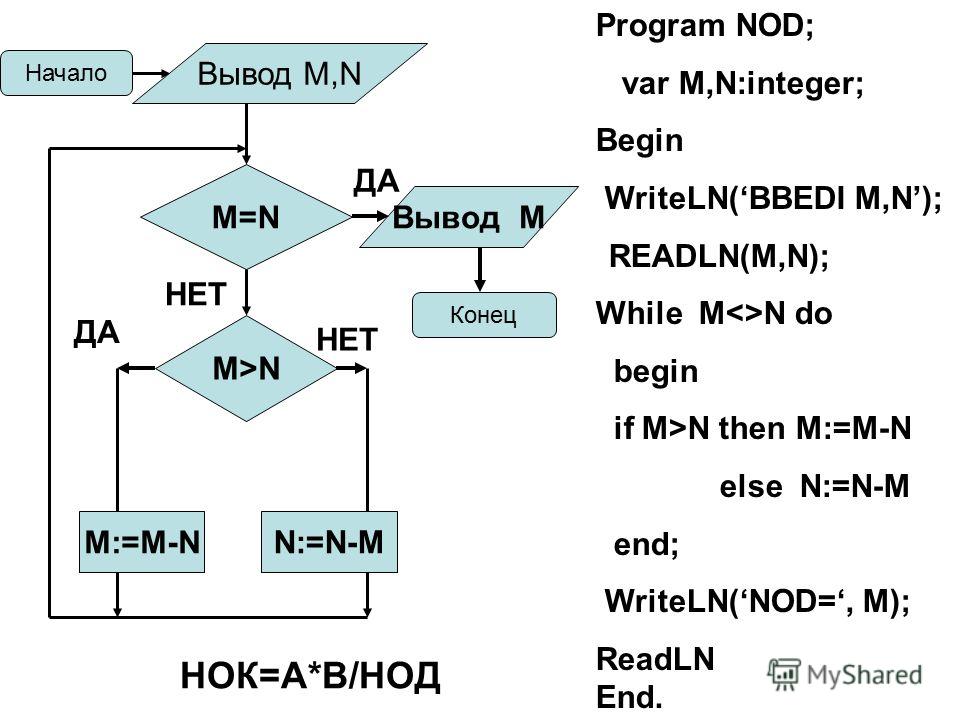
ПРЕДСТАВЛЕНИЕ АЛГОРИТМОВ С ПОМОЩЬЮ БЛОК-СХЕМ.
Ввод или вывод данных
начало
Проверка условия
нет
да
конец
вычисления
Изображение основных блоков:
да
С:=А
конец
А>B
С:=В
начало
Ввод А, В
Да
Нет
Вывод С
начало
Ввод А, В
S=A*B
Конец
Вывод S
Примеры:
Рис2. Нахождение наибольшего числа
Рис.1 Определение площади стола
Ошибки в алгоритмах
1. Синтаксические. Если при составлении алгоритма Роботу вместо «вправо» скомандуем «вправа» то ЭВМ нашу запись не поймет и, даже не приступая к выполнению алгоритма, сообщит об ошибке.
2. Отказы — проявляются при выполнении алгоритма, например, при попытке исполнителя Робот выйти за пределы поля или попытке деления на 0. В этом случае выполнение алгоритма или программы прекратится, и ЭВМ сообщит об ошибке.
3. Логические ошибки, которые ни ЭВМ, ни исполнитель вообще не могут обнаружить. Например, если мы вместо команды “вправо” напишем случайно “влево”, Робот выполнит алгоритм, но мы не попадем в ту клетку, куда было надо. Или если вместо команды S=A*B мы напишем S=A/B, ЭВМ все равно выполнит эту команду. Однако никаких сообщений об ошибках мы не получим (да и откуда ЭВМ может знать, куда мы на самом деле хотели переместить Робота, или по какой формуле мы хотели считать).
Что такое «компьютерный алгоритм»?
Чтобы заставить компьютер что-либо делать, вы должны написать компьютерную программу. Чтобы написать компьютерную программу, вы должны шаг за шагом сказать компьютеру, что именно вы хотите, чтобы он делал. Затем компьютер «выполняет» программу, механически следуя за каждым шагом, для достижения конечной цели.
Когда вы сообщаете компьютеру , что делать , вы также можете выбрать , как будет это делать. Вот тут-то и пригодятся компьютерных алгоритмов .Алгоритм — это основной метод, используемый для выполнения работы. Давайте рассмотрим пример, который поможет понять концепцию алгоритма.
Объявление
Допустим, у вас есть друг, прибывающий в аэропорт, и вашему другу нужно добраться из аэропорта к вам домой. Вот четыре различных алгоритма, которые вы можете дать своему другу, чтобы добраться до дома:
Алгоритм такси :
- Подойдите к стоянке такси.
- Садись в такси.
- Сообщите водителю мой адрес.
Алгоритм вызова по телефону :
- Когда прилетит ваш самолет, позвони мне на мобильный.
- Встретимся вне зоны выдачи багажа.
Алгоритм аренды автомобиля :
- Воспользуйтесь маршруткой до пункта проката автомобилей.
- Прокат авто.
- Следуйте указателям, чтобы добраться до моего дома.
Алгоритм шины :
- Вне выдачи багажа, автобус № 70.
- Пересадка на автобус 14 по Мейн-стрит.
- Сойти на улице Вязов.
- Пройдите два квартала на север до моего дома.
Все четыре этих алгоритма достигают одной и той же цели, но каждый алгоритм делает это совершенно по-разному. У каждого алгоритма разная стоимость и разное время в пути. Например, такси, вероятно, самый быстрый, но и самый дорогой способ. Автобус определенно дешевле, но намного медленнее.Вы выбираете алгоритм исходя из обстоятельств.
В компьютерном программировании часто существует множество различных способов — алгоритмов — для выполнения любой заданной задачи. Каждый алгоритм имеет свои преимущества и недостатки в разных ситуациях. Сортировка — это то место, где было проведено много исследований, потому что компьютеры тратят много времени на сортировку списков. Вот пять различных алгоритмов, которые используются при сортировке:
- Сортировка корзин
- Сортировка слиянием
- Сортировка пузырьков
- Сортировка по скорлупе
- Quicksort
Если у вас есть миллион целочисленных значений от 1 до 10 и вам нужно их отсортировать, то алгоритм bin sort — правильный алгоритм. Если у вас миллион названий книг, лучшим алгоритмом может быть quicksort . Зная сильные и слабые стороны различных алгоритмов, вы выбираете лучший для решения поставленной задачи.
Если у вас миллион названий книг, лучшим алгоритмом может быть quicksort . Зная сильные и слабые стороны различных алгоритмов, вы выбираете лучший для решения поставленной задачи.
Вот несколько интересных ссылок:
.Алгоритм
— что такое NP-Complete в информатике?
Переполнение стека
- Около
- Товары
- Для команд
- Переполнение стека Общественные вопросы и ответы
- Переполнение стека для команд Где разработчики и технологи делятся частными знаниями с коллегами
- Вакансии Программирование и связанные с ним технические возможности карьерного роста
- Талант Нанимайте технических специалистов и создавайте свой бренд работодателя
- Рекламная
.
Чем занимается специалист по алгоритмам?
Специалист по алгоритмам — это компьютерный ученый, который исследует и разрабатывает алгоритмы для академических и реальных приложений.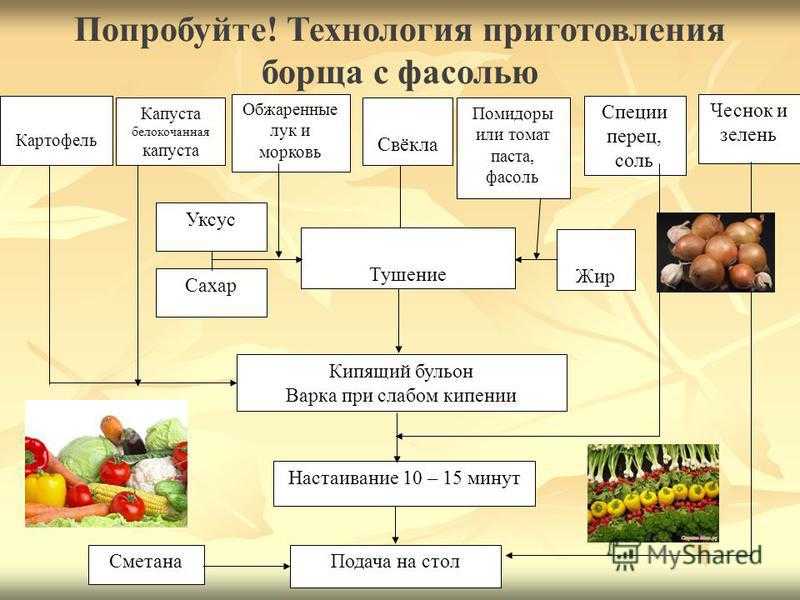 Алгоритмы — это последовательности инструкций, которые выполняют различные типы задач, и их можно разделить на категории по длительности их выполнения. Человек, изучающий алгоритмы, тратит много времени, пытаясь найти способы заменить более быстрые последовательности инструкций на последовательности, которые усложняют алгоритм.
Алгоритмы — это последовательности инструкций, которые выполняют различные типы задач, и их можно разделить на категории по длительности их выполнения. Человек, изучающий алгоритмы, тратит много времени, пытаясь найти способы заменить более быстрые последовательности инструкций на последовательности, которые усложняют алгоритм.
Как анализируются алгоритмы
Самые медленные алгоритмы требуют экспоненциального количества шагов по отношению к количеству входных значений. Самые быстрые алгоритмы могут выполняться за некоторое постоянное количество шагов, и на них не влияет количество входных значений. При разработке алгоритмов количество входных значений представлено переменной n, и иногда дополнительные переменные используются для алгоритмов, время работы которых зависит от размеров более чем одного набора входных значений.п) время.
Одной из наиболее важных областей исследования алгоритмов является проблема сравнения P и NP, или алгоритмов с полиномиальным временем и недетерминированных алгоритмов с полиномиальным временем. C), где C — любая константа.
C), где C — любая константа.
Рабочая среда для исследований в области компьютерных наук
Для того, чтобы стать специалистом по алгоритмам, обычно требуется докторская степень. Эти ученые разрабатывают программы для выполнения сложной работы, такой как автоматическая финансовая торговля, искусственный интеллект, интеллектуальный анализ данных, физическое моделирование и квантовые вычисления. Компьютерные исследователи могут быть наняты университетами или компаниями, инвестирующими в технологии алгоритмов, такими как IBM и Google. Знаменитым примером работы этих ученых является компьютерная программа Watson, которая участвовала в конкурсе Jeopardy в 2011 году.IBM разработала Watson для игры против людей на Jeopardy, и ей удалось победить двух бывших чемпионов Jeopardy, занимавших первое место.
Исследователи алгоритмов также нанимаются банками и инвестиционными фондами для создания программного обеспечения для автоматической торговли, которое снижает риск совершения сотен или тысяч сделок для паевых инвестиционных фондов и других типов инвестиций.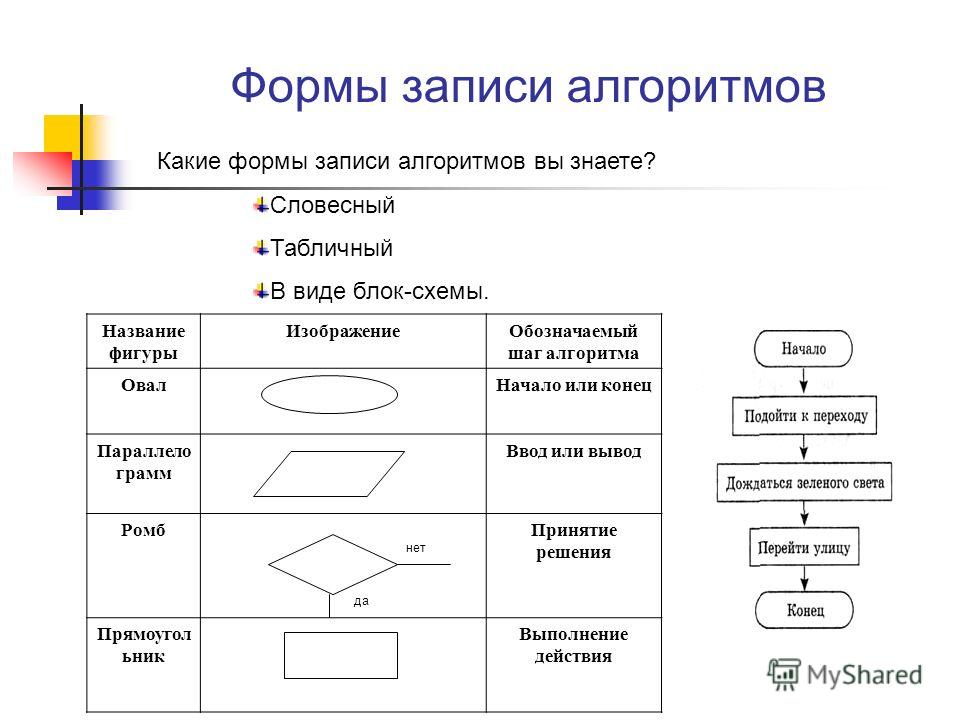 По данным Бюро статистики труда США, в 2012 году эти исследователи получали среднюю годовую зарплату в размере 102 190 долларов США, и ожидается, что в течение следующих десяти лет отрасль вырастет на 15 процентов.В развитии компьютерных технологий исследование алгоритмов не менее важно, чем инновации в оборудовании, поскольку более быстрые алгоритмы позволяют существующему оборудованию работать более эффективно. В настоящее время разработки программного обеспечения значительно больше, чем разработки оборудования.
По данным Бюро статистики труда США, в 2012 году эти исследователи получали среднюю годовую зарплату в размере 102 190 долларов США, и ожидается, что в течение следующих десяти лет отрасль вырастет на 15 процентов.В развитии компьютерных технологий исследование алгоритмов не менее важно, чем инновации в оборудовании, поскольку более быстрые алгоритмы позволяют существующему оборудованию работать более эффективно. В настоящее время разработки программного обеспечения значительно больше, чем разработки оборудования.
Исследование алгоритмов требует большой любви к математике и количественному решению задач. На получение докторской степени обычно уходит от шести до восьми лет, а докторская степень по информатике — одна из самых трудных для получения степени. Если вы увлечены дискретной математикой и хотите совершить прорыв в информатике, подумайте о том, чтобы стать специалистом по алгоритмам.
.
основ машинного обучения с алгоритмом K-ближайших соседей | by Onel Harrison
Алгоритм k-ближайших соседей (KNN) — это простой, легко реализуемый алгоритм контролируемого машинного обучения, который можно использовать для решения задач классификации и регрессии. Пауза! Давайте распакуем это.
Пауза! Давайте распакуем это.
ABC. Мы делаем это очень просто!
Алгоритм машинного обучения с учителем (в отличие от алгоритма машинного обучения без учителя) — это алгоритм, который полагается на помеченные входные данные для изучения функции, которая производит соответствующий результат при получении новых немаркированных данных.
Представьте, что компьютер — это ребенок, мы — его руководитель (например, родитель, опекун или учитель), и мы хотим, чтобы ребенок (компьютер) узнал, как выглядит свинья. Мы покажем ребенку несколько разных картинок, некоторые из которых — это свиньи, а остальные могут быть изображениями чего угодно (кошек, собак и т. Д.).
Когда мы видим свинью, мы кричим «свинья!» Когда это не свинья, мы кричим: «Нет, не свинья!» Проделав это с ребенком несколько раз, мы показываем ему картинку и спрашиваем: «Свинья?» и они будут правильно (в большинстве случаев) сказать «свинья!» или «нет, не свинья!» в зависимости от того, что на картинке.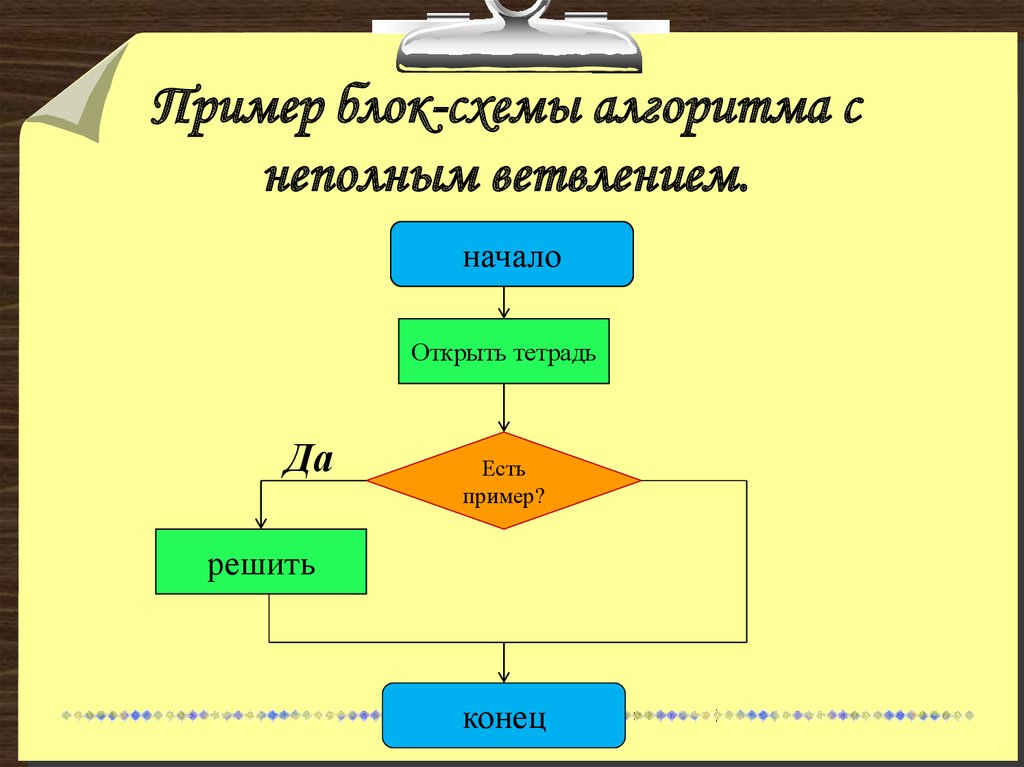 Это машинное обучение с учителем.
Это машинное обучение с учителем.
«Свинья!»
Алгоритмы машинного обучения с учителем используются для решения задач классификации или регрессии.
Задача классификации имеет дискретное значение на выходе. Например, «любит ананас на пицце» и «не любит ананас на пицце» дискретны. Там нет никакого среднего. Вышеупомянутая аналогия с обучением ребенка распознавать свинью является еще одним примером проблемы классификации.
Изображение, показывающее случайно сгенерированные данные
На этом изображении показан базовый пример того, как могут выглядеть данные классификации.У нас есть предиктор (или набор предикторов) и метка. На изображении мы, возможно, пытаемся предсказать, любит ли кто-то ананас (1) в пицце или нет (0), в зависимости от его возраста (предсказатель).
Стандартной практикой является представление вывода (метки) алгоритма классификации в виде целого числа, такого как 1, -1 или 0. В этом случае эти числа являются чисто репрезентативными. Математические операции над ними не должны выполняться, потому что это было бы бессмысленно. Задумайтесь на минутку.Что значит «любит ананас» + «не любит ананас»? Именно. Мы не можем добавлять их, поэтому мы не должны добавлять их числовые представления.
В этом случае эти числа являются чисто репрезентативными. Математические операции над ними не должны выполняться, потому что это было бы бессмысленно. Задумайтесь на минутку.Что значит «любит ананас» + «не любит ананас»? Именно. Мы не можем добавлять их, поэтому мы не должны добавлять их числовые представления.
Задача регрессии имеет на выходе действительное число (число с десятичной точкой). Например, мы могли бы использовать данные в таблице ниже, чтобы оценить вес человека с учетом его роста.
Изображение, показывающее часть набора данных высоты и весов SOCR.
Данные, используемые в регрессионном анализе, будут похожи на данные, показанные на изображении выше.У нас есть независимая переменная (или набор независимых переменных) и зависимая переменная (то, что мы пытаемся угадать с учетом наших независимых переменных). Например, мы могли бы сказать, что рост является независимой переменной, а вес — зависимой переменной.
Кроме того, каждая строка обычно называется примером , наблюдением или точкой данных , в то время как каждый столбец (не включая метку / зависимую переменную) часто называется предиктором , измерением, независимой переменной или функцией.
Алгоритм неконтролируемого машинного обучения использует входные данные без каких-либо ярлыков — другими словами, учитель (ярлык) не сообщает ребенку (компьютеру), когда он прав или когда он сделал ошибку, чтобы он мог -верный.
В отличие от обучения с учителем, которое пытается изучить функцию, которая позволит нам делать прогнозы на основании некоторых новых немаркированных данных, обучение без учителя пытается изучить базовую структуру данных, чтобы дать нам более глубокое понимание данных.
Алгоритм KNN предполагает, что похожие объекты существуют в непосредственной близости. Другими словами, похожие вещи находятся рядом друг с другом.
«Птицы стая падают».
Изображение, показывающее, как похожие точки данных обычно существуют близко друг к другу.
Обратите внимание на изображение выше, что большую часть времени похожие точки данных расположены близко друг к другу. Алгоритм KNN зависит от того, насколько верно это предположение, чтобы алгоритм был полезен. KNN улавливает идею сходства (иногда называемого расстоянием, близостью или близостью) с некоторой математикой, которую мы, возможно, усвоили в детстве, — вычислением расстояния между точками на графике.
Примечание: Прежде чем двигаться дальше, необходимо понять, как мы рассчитываем расстояние между точками на графике. Если вы не знакомы с этим расчетом или нуждаетесь в нем заново, полностью прочтите « Расстояние между 2 точками » и сразу же вернитесь.
Существуют и другие способы расчета расстояния, и один из них может быть предпочтительнее в зависимости от решаемой проблемы. Однако расстояние по прямой (также называемое расстоянием Евклида) — популярный и знакомый выбор.
Однако расстояние по прямой (также называемое расстоянием Евклида) — популярный и знакомый выбор.
Алгоритм KNN
- Загрузите данные
- Инициализируйте K для выбранного количества соседей
3. Для каждого примера в данных
3.1 Вычислите расстояние между примером запроса и текущим примером по данным.
3.2 Добавьте расстояние и индекс примера в упорядоченную коллекцию
4. Отсортируйте упорядоченную совокупность расстояний и индексов от наименьшего к наибольшему (в порядке возрастания) по расстояниям
5.Выберите первые K записей из отсортированной коллекции
6. Получите метки выбранных K записей
7. В случае регрессии верните среднее значение K меток
8. При классификации верните режим K меток
Реализация KNN (с нуля)
Выбор правильного значения для K
Чтобы выбрать K, который подходит для ваших данных, мы запускаем алгоритм KNN несколько раз с разными значениями K и выбираем K, который уменьшает количество ошибок мы сталкиваемся, сохраняя при этом способность алгоритма точно делать прогнозы, когда ему предоставляются данные, которых он раньше не видел.
Вот некоторые вещи, о которых следует помнить:
- По мере того, как мы уменьшаем значение K до 1, наши прогнозы становятся менее стабильными. Подумайте на минуту, представьте, что K = 1 и у нас есть точка запроса, окруженная несколькими красными и одним зеленым (я думаю о верхнем левом углу цветного графика выше), но зеленый — единственный ближайший сосед. Разумно, мы могли бы подумать, что точка запроса, скорее всего, красная, но поскольку K = 1, KNN неправильно предсказывает, что точка запроса зеленая.
- И наоборот, когда мы увеличиваем значение K, наши прогнозы становятся более стабильными из-за большинства голосов / усреднения и, следовательно, с большей вероятностью будут делать более точные прогнозы (до определенного момента).В конце концов, мы начинаем замечать все большее количество ошибок. Именно в этот момент мы знаем, что зашли слишком далеко в значении K.
- В случаях, когда мы принимаем большинство голосов (например, выбираем режим в задаче классификации) среди меток, мы обычно делаем K нечетным числом, чтобы иметь возможность разрешить ничью.

Преимущества
- Алгоритм прост и удобен в реализации.
- Нет необходимости строить модель, настраивать несколько параметров или делать дополнительные предположения.
- Алгоритм универсален. Его можно использовать для классификации, регрессии и поиска (как мы увидим в следующем разделе).
Недостатки
- Алгоритм становится значительно медленнее по мере увеличения количества примеров и / или предикторов / независимых переменных.
Главный недостаток KNN в том, что он становится значительно медленнее по мере увеличения объема данных, что делает его непрактичным выбором в средах, где нужно делать прогнозы быстро.Более того, существуют более быстрые алгоритмы, которые могут дать более точные результаты классификации и регрессии.
Однако при условии, что у вас достаточно вычислительных ресурсов для быстрой обработки данных, которые вы используете для прогнозирования, KNN может быть полезен при решении проблем, решения которых зависят от идентификации похожих объектов. Примером этого является использование алгоритма KNN в рекомендательных системах, приложение KNN-поиска.
Примером этого является использование алгоритма KNN в рекомендательных системах, приложение KNN-поиска.
Рекомендательные системы
В масштабе это выглядело бы как рекомендация продуктов на Amazon, статей на Medium, фильмов на Netflix или видео на YouTube.Хотя мы можем быть уверены, что все они используют более эффективные способы предоставления рекомендаций из-за огромного объема данных, которые они обрабатывают.
Однако мы могли бы воспроизвести одну из этих рекомендательных систем в меньшем масштабе, используя то, что мы узнали здесь, в этой статье. Давайте создадим ядро рекомендательной системы фильмов.
На какой вопрос мы пытаемся ответить?
Учитывая наш набор данных о фильмах, какие 5 фильмов наиболее похожи на запрос фильма?
Сбор данных о фильмах
Если бы мы работали в Netflix, Hulu или IMDb, мы могли бы получить данные из их хранилищ данных.Поскольку мы не работаем ни в одной из этих компаний, нам приходится получать наши данные другими способами. Мы могли бы использовать некоторые данные фильмов из репозитория машинного обучения UCI, набор данных IMDb или кропотливо создать свои собственные.
Мы могли бы использовать некоторые данные фильмов из репозитория машинного обучения UCI, набор данных IMDb или кропотливо создать свои собственные.
Изучить, очистить и подготовить данные
Где бы мы ни получали наши данные, в них могут быть некоторые ошибки, которые нам необходимо исправить, чтобы подготовить их для алгоритма KNN. Например, данные могут быть не в том формате, который ожидает алгоритм, или могут быть отсутствующие значения, которые мы должны заполнить или удалить из данных, прежде чем передавать их в алгоритм.
Наша реализация KNN, описанная выше, основана на структурированных данных. Он должен быть в виде таблицы. Кроме того, реализация предполагает, что все столбцы содержат числовые данные и что последний столбец наших данных имеет метки, с которыми мы можем выполнять некоторые функции. Итак, откуда бы мы ни брали данные, нам нужно привести их в соответствие этим ограничениям.
Приведенные ниже данные являются примером того, на что могут быть похожи наши очищенные данные. Данные содержат тридцать фильмов, включая данные по каждому фильму семи жанров и их рейтинги IMDB.В столбце ярлыков все нули, потому что мы не используем этот набор данных для классификации или регрессии.
Данные содержат тридцать фильмов, включая данные по каждому фильму семи жанров и их рейтинги IMDB.В столбце ярлыков все нули, потому что мы не используем этот набор данных для классификации или регрессии.
Набор данных рекомендаций по самодельным фильмам
Кроме того, существуют отношения между фильмами, которые не будут учитываться (например, актеры, режиссеры и темы) при использовании алгоритма KNN просто потому, что данные, которые фиксируют эти отношения, отсутствуют в данных устанавливать. Следовательно, когда мы запускаем алгоритм KNN на наших данных, сходство будет основываться исключительно на включенных жанрах и рейтингах фильмов на IMDB.
Используйте алгоритм
Представьте себе на мгновение. Мы просматриваем веб-сайт MoviesXb, вымышленное дочернее предприятие IMDb, и встречаем The Post . Мы не уверены, что хотим его смотреть, но нас заинтриговали его жанры; нам интересно узнать о других подобных фильмах.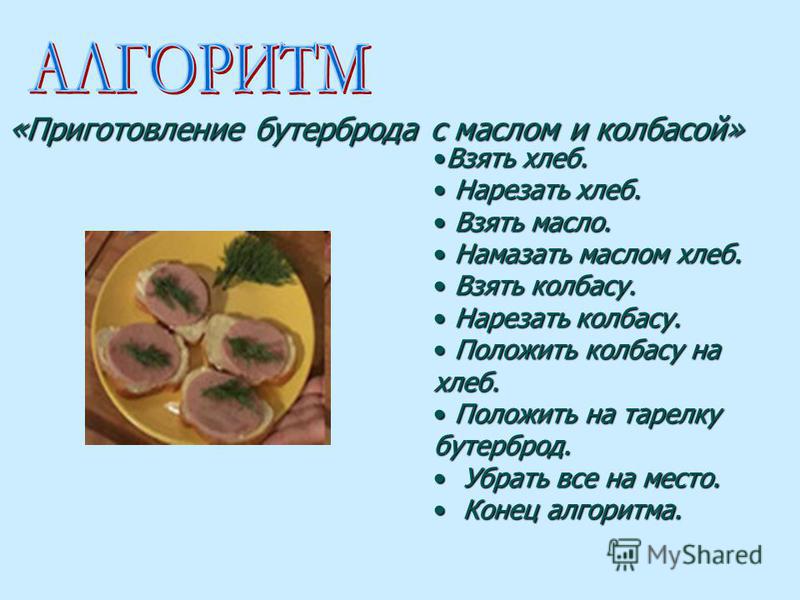 Мы прокручиваем вниз до раздела «Еще как это», чтобы увидеть, какие рекомендации сделает MoviesXb, и алгоритмические механизмы начинают вращаться.
Мы прокручиваем вниз до раздела «Еще как это», чтобы увидеть, какие рекомендации сделает MoviesXb, и алгоритмические механизмы начинают вращаться.
Веб-сайт MoviesXb отправляет запрос на свой сервер для 5 фильмов, наиболее похожих на The Post .Бэкэнд имеет набор данных рекомендаций, точно такой же, как у нас. Он начинается с создания представления строки (более известного как вектор функций ) для The Post , затем запускается программа, аналогичная приведенной ниже, для поиска 5 фильмов, наиболее похожих на The Post , и наконец, отправляет результаты обратно на сайт MoviesXb.
Когда мы запускаем эту программу, мы видим, что MoviesXb рекомендует 12 Years A Slave , Hacksaw Ridge , Queen of Katwe , The Wind Rises и A Beautiful Mind .Теперь, когда мы полностью понимаем, как работает алгоритм KNN, мы можем точно объяснить, как алгоритм KNN дал эти рекомендации. Поздравляю!
Алгоритм k-ближайших соседей (KNN) — это простой алгоритм машинного обучения с учителем, который можно использовать для решения задач классификации и регрессии.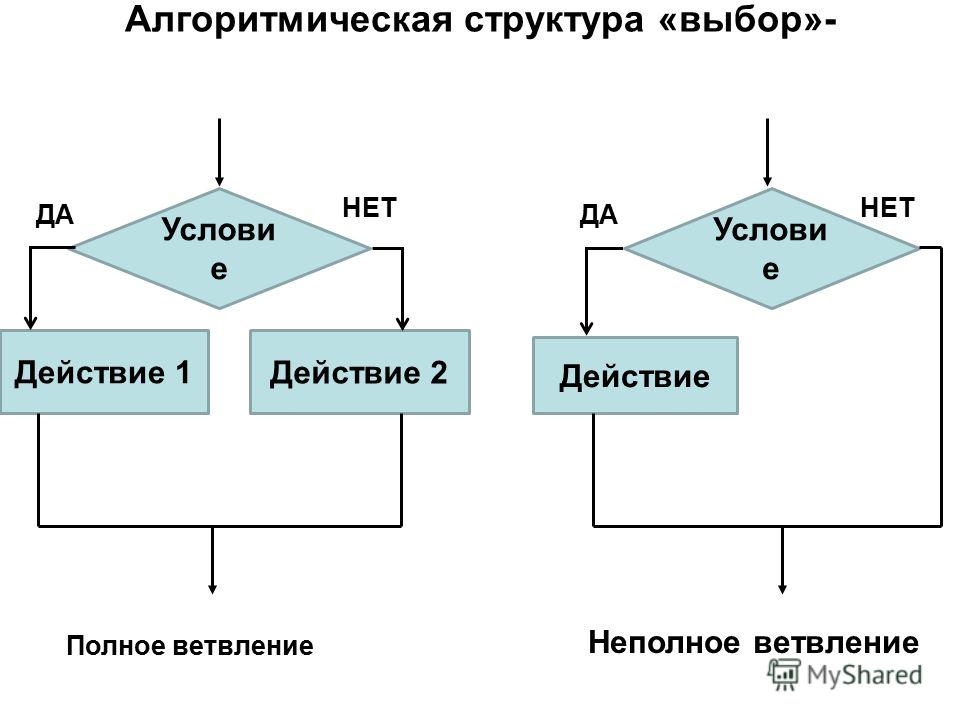 Его легко реализовать и понять, но у него есть серьезный недостаток: он значительно замедляется по мере роста размера используемых данных.
Его легко реализовать и понять, но у него есть серьезный недостаток: он значительно замедляется по мере роста размера используемых данных.
KNN работает, находя расстояния между запросом и всеми примерами в данных, выбирая указанное число примеров (K), ближайших к запросу, затем голосует за наиболее частую метку (в случае классификации) или усредняет метки (в случае регресса).
В случае классификации и регрессии мы увидели, что выбор правильного K для наших данных осуществляется путем проверки нескольких K и выбора того, который работает лучше всего.
Наконец, мы рассмотрели пример того, как алгоритм KNN может быть использован в рекомендательных системах, приложение KNN-поиска.
.
Технологическая карта урока информатики по теме «Что такое алгоритм»
 org/Person»>
org/Person»>Котова Ольга Ивановна
Разделы:
Информатика
Класс: 7.
Тип урока: освоение нового материала.
Форма проведения урока: применение интерактивного оборудования и интернет-ресурсов.
Цели урока:
- познакомиться с определением «Алгоритм»;
- сформировать способности составлять, корректировать алгоритмы;
- научить видеть и устранять ошибки в алгоритмах.
Задачи:
- создание условий для формирования мышления, логики, познавательного интереса;
- воспитание решительности при достижении поставленной цели, ответственности за итоги своего труда, почтения к мнению одноклассников, дружеского отношения, чувства взаимовыручки.

Планируемые результаты:
Личностные результаты:
- готовность и склонность обучающихся к саморазвитию;
- навыки партнёрства в различных ситуациях, умение не конкурировать и находить выходы из проблемных ситуаций.
Метапредметные результаты.
Познавательные:
- компетентность познавательных интересов, нацеленных на развитие представлений об алгоритмах;
- умение работать с разными источниками информации, включая электронные.
Регулятивные:
- осознание смысла поставленной задачи;
- умение выполнять задания в соответствии с целью.
Коммуникативные:
- сформированность умений грамотно излагать свои мысли в устной речи;
- умение правильно использовать речевые средства для формулировки своей позиции;
- умение работать сообща в группах.
Предметные результаты:
- знание понятия алгоритм и его свойств;
- корректное составление алгоритмов;
- применение новых знаний в новой ситуации;
- пользоваться учебником для нахождения информации;
- самостоятельно использовать знания в решении задач.
Ресурсы:
- презентация «Алгоритм».
- Флэш-ролики «Слепи снеговика», «Почисти ковёр», «Погладь рубашку», «Свойства алгоритмов». Единая коллекция ЦОР.
Ход урока
Деятельность учителя | Деятельность учеников | Время |
1. Организационный момент Доброе утро, ребята! Я рада снова вас видеть. | Приготовились к уроку и настроились на него. | 1 мин |
2. Вступительная беседа. Актуализация знаний Кстати, ребята, а кто из вас смотрел мультфильм «Алиса в стране чудес»? | ||
— Как вы думаете, что имел в виду Кот? Да, ребята, эти слова имеют глубочайший смысл. Зачастую мы не находим решения задачи или какой-нибудь трудности из-за того, что не можем построить грамотно очерёдность своих действий. Сообразительный человек знает: чтобы не угодить впросак и добиться желаемой цели, нужно предварительно просчитывать и планировать свои действия. | — Должна быть цель. | 2 мин |
| А как это сделать? | Нужно разработать план действий. | |
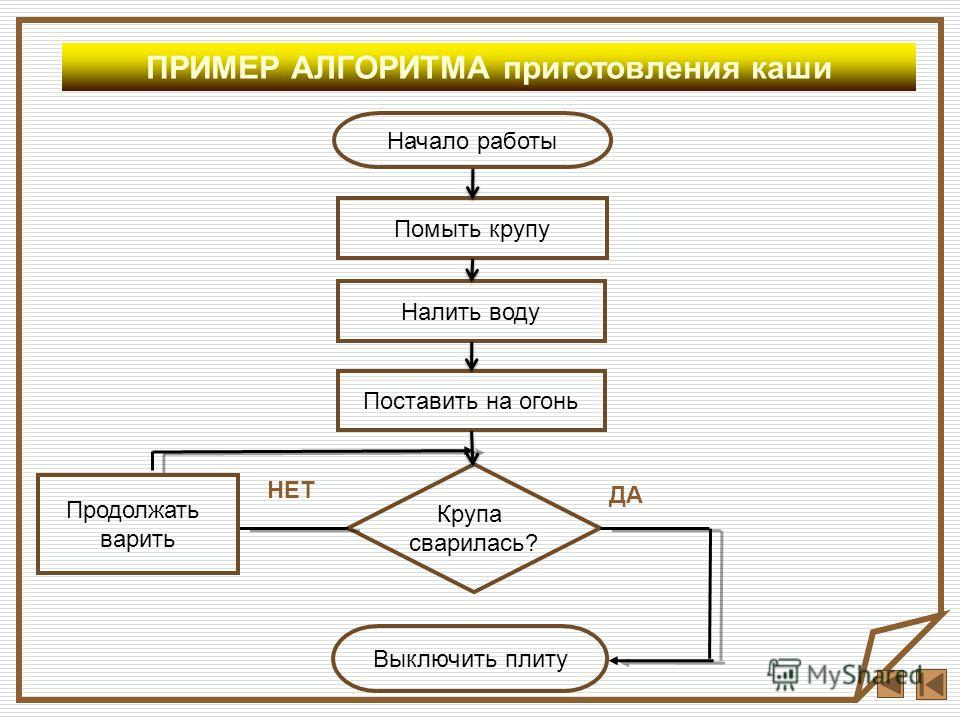
3. Освоение нового материала А подробный план действий — это и есть …Узнаете, расшифровав ребус. | Алгоритм | 10 мин |
— Какие цели мы поставим перед собой? — Чтобы достичь итога, нужно поставить цель и иметь план действий. Но порой бывает и такое. Посмотрите отрывок из мультфильма «Вовка в Тридевятом царстве» и попробуйте ответить на вопрос: «Почему двое из ларца не смогли замесить тесто и нарубить поленья? ». (Видео) | · Выяснить что такое алгоритм? · Научиться составлять алгоритм.  · Выполнить работу по написанию алгоритмов. | |
| — Почему двое из ларца не смогли замесить тесто и нарубить дрова? В информатике то, с чем надо работать называются исходными данными, а чёткие указания-конечная последовательность действий. | Не было чётких указаний кому и что надо делать и с чем. То, с чем надо работать называются … (исходными данными), а точные указания — это … (конечная последовательность действий). | |
| Исходя из целей нашего урока, мы должны выяснить, что такое «алгоритм». А может быть, кто-то уже может проговорить, что такое «алгоритм»? | Алгоритм — понятное и точное предписание исполнителю выполнить конечную последовательность команд, приводящую от исходных данных к результату. | |
А где мы можем отыскать информацию о том, что такое алгоритм? Работа с разнообразными источниками информации. | В учебнике, словарях, интернете. | |
| Как вы думаете, кто является проектировщиком алгоритма? А исполнителем алгоритма? | Только человек. Человек, роботы, машины, бытовая техника, и т.д. | |
4. Первичное осознание и расширение знаний — Итак, ребята, мы получили новые знания о том, что такое «алгоритм». И выясняется, с понятием алгоритм мы встречаемся постоянно. У вас на партах карточки с примерами из жизни. | Ищут в примерах алгоритмы. Купить хлеб | 7 мин |
5. Физкультпауза | Повторяют движения с экрана. | 2 мин |
6. Первичное закрепление освоенного материала Итак, мы познакомились с понятием «алгоритм» привели примеры алгоритмов из жизни. Теперь мы попробуем сами создать алгоритм. Вам нужно создать один из предоставленных алгоритмов: | Выполняют задание. | 4 мин |
7. Самостоятельная работа по проверке осмысления материала Чтобы проверить ваши знания, проведём самостоятельную работу, при выполнении которой вы будете использовать следующий алгоритм: | Выполняют задание. | 10 мин |
8. Рефлексия учебной деятельности Ребята, наш маршрут подошёл к финалу. Мы сумели устранить все препятствия и добиться результата. | Наклеивают лепесток определённого цвета на доске. | 1 мин |
9. Разработайте алгоритм приготовления вашего любимейшего блюда. | Записывают домашнее задание в тетрадь | 1 мин |
10. Подведение итогов урока Итак, какая была тема урока? Чему вы научились на уроке?
Ребята, мне невероятно понравилось, как вы трудились на уроке, умело формулировали свои мысли, могли договориться друг с другом. Спасибо за урок! | Что такое алгоритм. | 2 мин |

 Домашнее задание
Домашнее задание
Свойства алгоритма и его исполнители (9 класс) Информатика и ИКТ
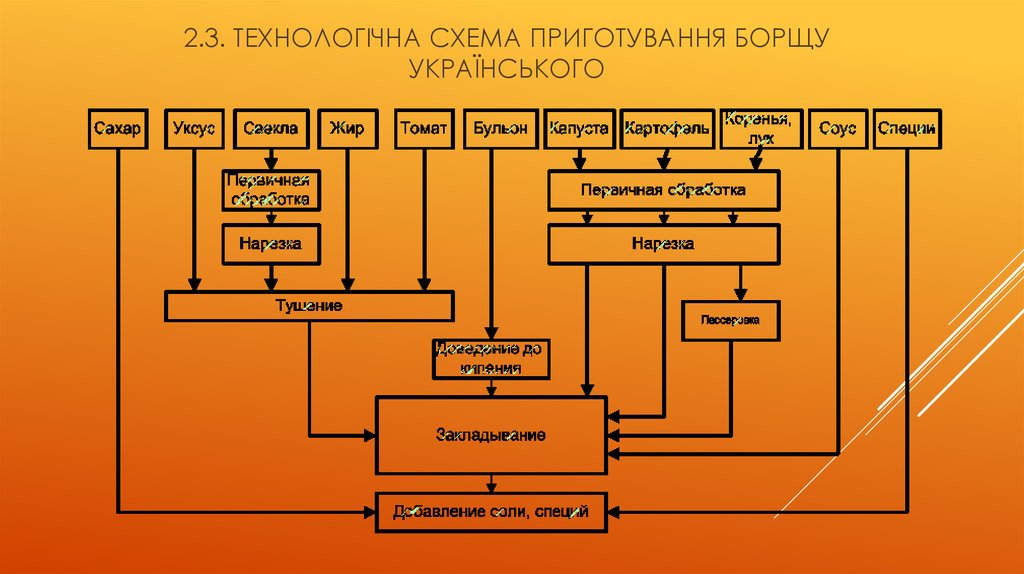
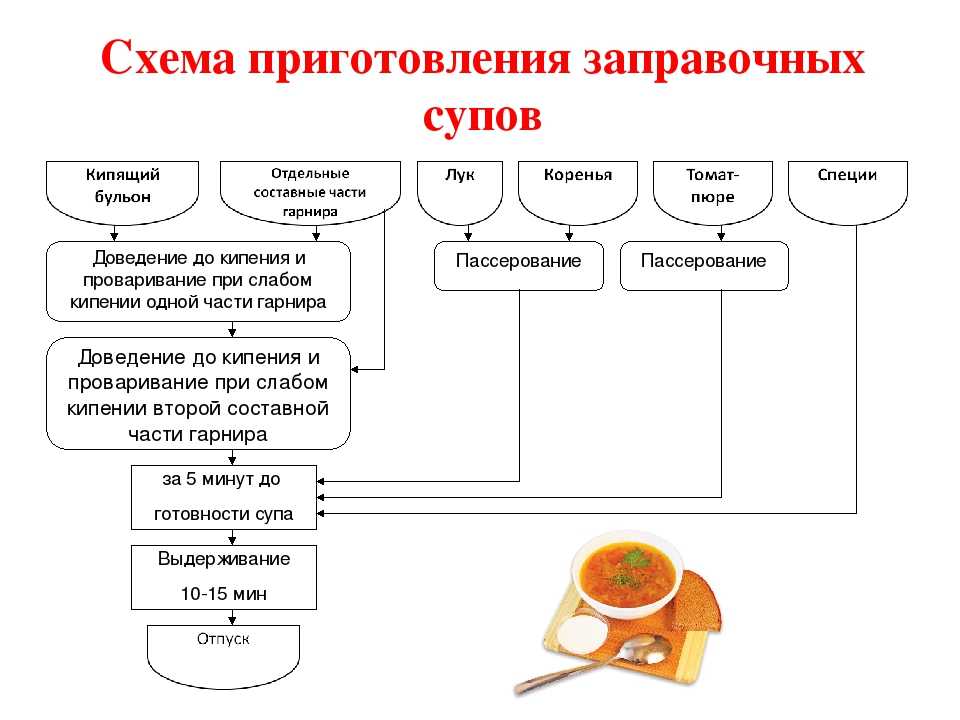
Во многих отраслях человеческой деятельности для достижения требуемого результата используются алгоритмы, содержащие четкие описания последовательности действий. Примерами алгоритмов являются кулинарные рецепты, в которых подробно описана последовательность действий по приготовлению пищи.
Примерами алгоритмов являются кулинарные рецепты, в которых подробно описана последовательность действий по приготовлению пищи.
Алгоритм приготовления блюда быстрого питания:
- Высыпать в емкость содержимое пакетика.
- Налить в емкость 200 мл горячей воды.
- Тщательно перемешать.
Дискретность.
Алгоритмы кулинарных рецептов состоят из отдельных действий, которые обычно нумеруются. Разделение алгоритма на последовательность шагов является важным свойством алгоритма и называется дискретностью.
Результативность.
Алгоритмами являются известные из начальной школы правила сложения, вычитания, умножения и деления столбиком. Применение этих алгоритмов независимо от количества разрядов в числах и, соответственно, количества вычислительных шагов алгоритма всегда приводит к результату. Получение из исходных данных результата за конечное число шагов называется результативностью алгоритма.
Алгоритм сложения целых чисел в десятичной системе счисления:
- Записать числа в столбик, так чтобы цифры самого младшего разряда чисел (единицы) расположились одна под другой (на одной вертикали).
- Сложить цифры младшего разряда.
- Записать результат под горизонтальной чертой на вертикали единиц, если при этом полученная сумма больше или равна величине основания системы счисления (в данном случае 10), перенести десятки в старший разряд десятков.
- Повторить пункты 2 и 3 для всех разрядов с учетом переносов из младших разрядов.

Массовость.
Алгоритмы сложения, вычитания, умножения и деления могут быть применены для любых чисел, причем не только в десятичной, но и в других позиционных системах счисления (двоичной, восьмеричной, шестнадцатеричной и др. ). Возможность применения алгоритма к большому количеству различных исходных данных называется массовостью.
Само слово «алгоритм» происходит от «algorithmi» — латинской формы написания имени выдающегося математика IX века аль-Хорезми, который сформулировал правила выполнения арифметических операций.
Исполнители алгоритмов.
Алгоритмы широко используются в технике в системах управления объектами. В любой системе управления существует управляющий объект, который является исполнителем алгоритма управления. Так, в системах терморегуляции для поддержания определенной температуры в помещении исполнителем алгоритма может являться как человек, так и микропроцессор.
В любой системе управления существует управляющий объект, который является исполнителем алгоритма управления. Так, в системах терморегуляции для поддержания определенной температуры в помещении исполнителем алгоритма может являться как человек, так и микропроцессор.
Алгоритм терморегуляции:
- Измерить температуру в помещении.
- Если измеренная температура ниже заданной, включить обогреватель.
Детерминированность.
При управлении самолетом используются сложные алгоритмы, исполнителями которых являются пилот или бортовой компьютер. Последовательность выполнения действий, например, при взлете должна быть строго определенной (например, нельзя отрываться от взлетной полосы, пока самолет не набрал необходимую взлетную скорость). Исполнитель алгоритма, выполнив очередную команду, должен точно знать, какую команду необходимо исполнять следующей. Это свойство алгоритма называется детерминированностью.
Выполнимость и понятность.
После включения компьютера начинают выполняться алгоритмы тестирования компьютера и загрузки операционной системы. Исполнителем этих алгоритмов является компьютер, поэтому они должны быть записаны на понятном компьютеру машинном языке.
Каждый исполнитель обладает определенным набором, системой команд, которые он может выполнить. Алгоритм должен быть понятен исполнителю, т. е. должен содержать
только те команды, которые входят в систему его команд.
Выше были приведены примеры алгоритмов из различных областей человеческой деятельности и знаний. В этих алгоритмах различные исполнители выполняли операции над объектами различной природы (материальными объектами и числами). При этом во всех примерах можно выделить следующие основные свойства алгоритма:
- Результативность и дискретность. Алгоритм должен обеспечивать получение из исходных данных результата за конечное число дискретных шагов.
- Массовость. Один и тот же алгоритм может применяться к большому количеству однотипных объектов.
- Детерминированность. Исполнитель должен выполнять команды алгоритма в строго определенной последовательности.
- Выполнимость и понятность. Алгоритм должен содержать команды, входящие в систему команд исполнителя и записанные на понятном исполнителю языке.

Алгоритм — это описание детерминированной последовательности действий, направленных на получение из исходных данных результата за конечное число дискретных шагов с помощью понятных исполнителю команд.
Формальное исполнение алгоритма.
Из приведенных выше свойств алгоритма вытекает возможность его формального выполнения. Это означает, что алгоритм можно выполнять, не вникая в содержание поставленной задачи, а только строго выполняя последовательность действий, описанных в алгоритме.
Контрольные вопросы:
- Приведите примеры известных вам алгоритмов.
- Перечислите основные свойства алгоритмов и проиллюстрируйте их примерами.
- Как вы понимаете формальное исполнение алгоритма?
Задания:
- Записать алгоритм вычитания столбиком целых чисел в десятичной системе счисления.
Содержание
| Понравилось? | Нравится | Твитнуть |
Задание 126 Приведите пример линейного алгоритма из повседневной жизни Информатика Босова Рабочая тетрадь 1 часть ► Информатика в школе и дома
Все статьи Решебник к Рабочей тетраде Информатика 8 класс Босова
Информатика и ИКТОставить комментарийна Задание 126 Приведите пример линейного алгоритма из повседневной жизни Информатика Босова Рабочая тетрадь 1 часть
Want create site? Find Free WordPress Themes and plugins.
Задание 126. Приведите пример линейного алгоритма из повседневной жизни или литературного произведения
1) Приведем пример линейного алгоритма из повседневной жизни:
Например рецепт приготовления любого блюда является линейным, например, приготовления бутерброда с маслом, с сыром, салата из моркови, чеснока и майонеза, просто алгоритм открывания замка.
Ученик на экзамене: подходит вытягивает билет, садится готовиться, отвечает, получает оценку, уходит
Утро ученика:
Проснуться в 6:50;
Сделать зарядку;
Позавтракать;
Умыться и почистить зубы;
Одеться;
Пойти в школу.
2) Приведем пример линейного алгоритма из литературного произведения:
«Сказка о царе Салтане»: алгоритм превращения лебедя в царевну:
Тут она, взмахнув крылами, Полетела над волнами И на берег с высоты Опустилася в кусты, Встрепенулась, отряхнулась И царевной обернулась
На этой странице размещен вариант решения заданий с страницы к рабочей тетради часть 1 по информатике за 8 класс авторов Босова. Здесь вы сможете списать решение домашнего задания или просто посмотреть ответы. ГДЗ, рабочая тетрадь часть 1
Литература:Рабочая тетрадь, часть 1,2. Информатика, 8 класс. Автор: Босова Л.Л., Босова А.Ю. Издательство: Бином
Did you find apk for android? You can find new Free Android Games and apps.
Найти:
Рубрики
РубрикиВыберите рубрикуIT Новости — технологии, софт, гаджеты со всего мира и России (347)Все статьи (1 778)ЕГЭ учебные пособия – Подготовка по информатике к экзамену скачать читать бесплатно (3)Информатика — учебники 1-11 класс онлайн читать (214) Учебники Информатики 1 класс онлайн, скачать, читать (5) Учебники Информатики 10 класс онлайн, скачать, читать (22) Учебники Информатики 11 класс онлайн, скачать, читать (18) Учебники Информатики 2 класс онлайн, скачать, читать (17) Учебники Информатики 3 класс онлайн, скачать, читать (28) Учебники Информатики 4 класс онлайн, скачать, читать (31) Учебники Информатики 5 класс онлайн, скачать, читать (19) Учебники Информатики 6 класс онлайн, скачать, читать (20) Учебники Информатики 7 класс онлайн, скачать, читать (35) Учебники Информатики 8 класс онлайн, скачать, читать (35) Учебники Информатики 9 класс онлайн, скачать, читать (37)КИМ Информатика 8 класс Масленикова (15)Методическая копилка — Дошкольная Информатика (3)Методическая копилка по информатике: уроки, конспекты, занимательные задачи (47) Методическая копилка по информатике — 5 класс — уроки, конспекты, занимательные задачи (3) Методическая копилка по информатике — 6 класс — уроки, конспекты, занимательные задачи (18)НОВОСТИ об ИГРАХ — новинки, обновления, свежие игровые новости (377)ОГЭ учебные пособия — Подготовка по информатике к экзамену скачать читать бесплатно (6)Решебник ГДЗ Информатика учебник 9 класс Угринович (22)Решебник ГДЗ Семакин Информатика 8 класс Учебник (27)Решебник ГДЗ Учебника Информатика 9 КЛАСС Босова Вопросы и задания (22)Решебник Информатика 2 класс Горячев, Горина, Суворова (128)Решебник Информатика 2 класс Матвеева, Челак (102)Решебник Информатика 3 класс Горячев, Горина, Суворова (72)Решебник Информатика 3 класс Матвеева, Челак (129)Решебник Информатика 4 класс Горячев, Горина, Суворова (105)Решебник Информатика 4 класс Матвеева, Челак (189)Решебник Информатика Рабочая тетрадь 9 класс Семакин (14)Решебник к Рабочей тетраде Информатика 5 класс Босова (131)Решебник к Рабочей тетраде Информатика 6 класс Босова (202)Решебник к Рабочей тетраде Информатика 7 класс Босова (147)Решебник к Рабочей тетраде Информатика 8 класс Босова (202)Решебник к учебнику Информатика 5 класс Босова (36)Решебник к учебнику Информатика 6 класс Босова (18)Решебник к учебнику Информатика 7 класс Босова (27)Решебник к учебнику Информатика 8 класс Босова (11)Решебник к учебнику Информатика 9 класс Семакин (27)Решебник учебника Информатика 8 класс Угринович (5)Решение задач по информатике для школьников (2 174) Задачи и советы по работе в MS Office — практика и теория (1 892) Практические работы в MS Access — задания, советы, решения и ответы (165) Практические работы в MS Excel — задания, советы, решения и ответы (1 285) Практические работы в MS Power Point — задания, советы, решения и ответы (145) Практические работы в MS Word — задания, советы, решения и ответы (297) Задачи по программированию с решением для школьников (267) Занимательные задачи по информатике для школьников (15)Сайтостроение — создать с нуля, уроки, новости, полезное (355)
Урок информатики на тему: «Алгоритм», 6-1 класс
- Библиотека
- Информатика
- Урок информатики на тему: «Алгоритм», 6-1 класс
Категория: Информатика.
Урок информатики на тему: «Алгоритм», 6-1 класс
Цели урока: Познакомить учащихся с понятием алгоритм и его свойствами.
Задачи урока:
- образовательная: Сформировать представление у учащихся о понятии алгоритма, выделить его свойства. Рассмотреть понятие исполнителя и системы команд исполнителя;
- развивающая: Формирование приемов логического мышления, развитие познавательного интереса к предмету;
- воспитательная: Воспитание аккуратности, точности. Формирование у учащихся целостных представлений о картине мира
Тип урока:
Урок изучения и первичного закрепления новых знаний
Используемое оборудование:
Персональный компьютер (рабочее место учителя), компьютерный класс (рабочие места учащихся), мультимедиа проектор, экран, принтер
Педагогические технологии: компьютерные (информационные) технологии
Используемые ЦОР:
Расставьте команды в алгоритме для робота: http://files.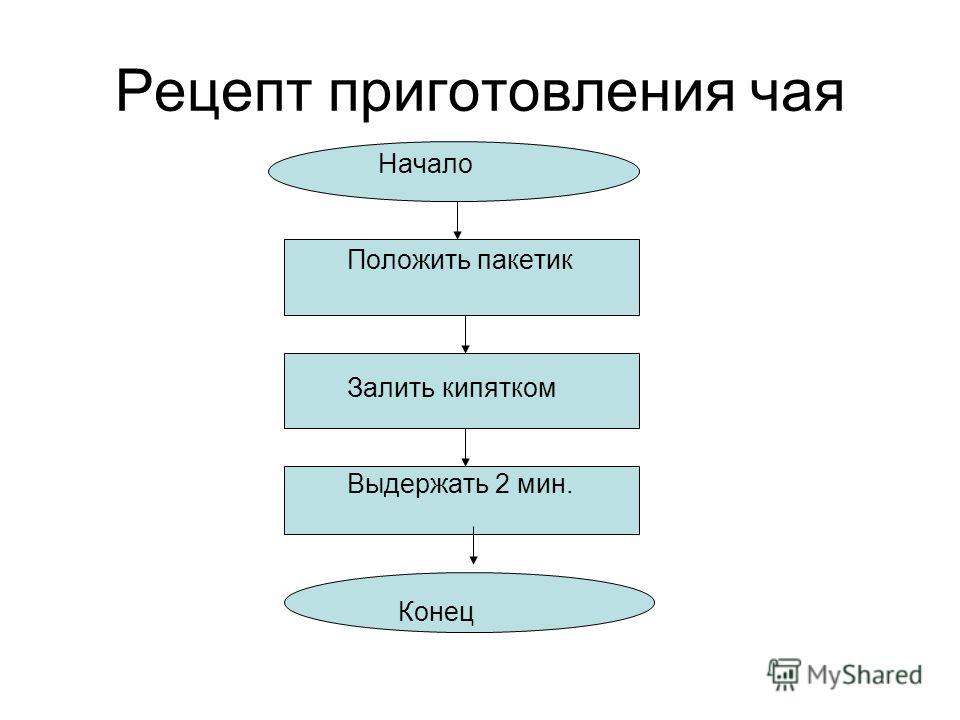 school-collection. edu. ru/dlrstore/e5fdb511-4a83-4865-a2a8-90292a4dfcad/%5BNS-INF_3-01-01-02%5D_%5BIM_153%5D. swf
school-collection. edu. ru/dlrstore/e5fdb511-4a83-4865-a2a8-90292a4dfcad/%5BNS-INF_3-01-01-02%5D_%5BIM_153%5D. swf
Исполнители алгоритмов: http://files. school-collection. edu. ru/dlrstore/58e9a0c3-11df-4c94-a5eb-b0a7b359ea35/9_32. swf
Откуда произошло слово Алгоритм: http://files. school-collection. edu. ru/dlrstore/88093ab9-6a3e-4bc6-8d5d-9b7434d8416b/9_31. swf
Свойства алгоритма http://files. school-collection. edu. ru/dlrstore/ef6533fd-06d1-4b38-9498-ac58430f845e/9_33. swf
Ветвление:http://files. school-collection. edu. ru/dlrstore/d49f2b6d-1862-449a-882c-2f3b712632e7/%5BNS-INF_4-01-01-02%5D_%5BIM_234%5D. swf
Краткое описание:
Вводный урок и разработанная презентация по теме «Алгоритм»направлены на пропедевтику курса «Алгоритмизация и программирование», способствует развитию познавательного интереса к предмету, воспитывает у учащихся ценностное отношение к информатике.
Ход урока.
| Деятельность учителя | Деятельность учащихся |
1. Вступительная беседа:Есть известное многим произведение Льюиса Кэррола «Алиса в стране чудес»: Вступительная беседа:Есть известное многим произведение Льюиса Кэррола «Алиса в стране чудес»:«Алиса спрашивает у кролика: – Куда мне надо идти? Мудрый кролик ей отвечает: – Все зависит от того, куда Вам надо прийти» Эти слова имеют глубокий смысл. Зачастую мы не находим решения задачи или какой-нибудь проблемы из-за того, что не можем выстроить правильно последовательность своих действий. Умный человек знает: чтобы не попасть впросак и добиться желаемой цели, нужно заранее продумывать и планировать свои действия. А как это сделать? | Нужно составить план своих действий |
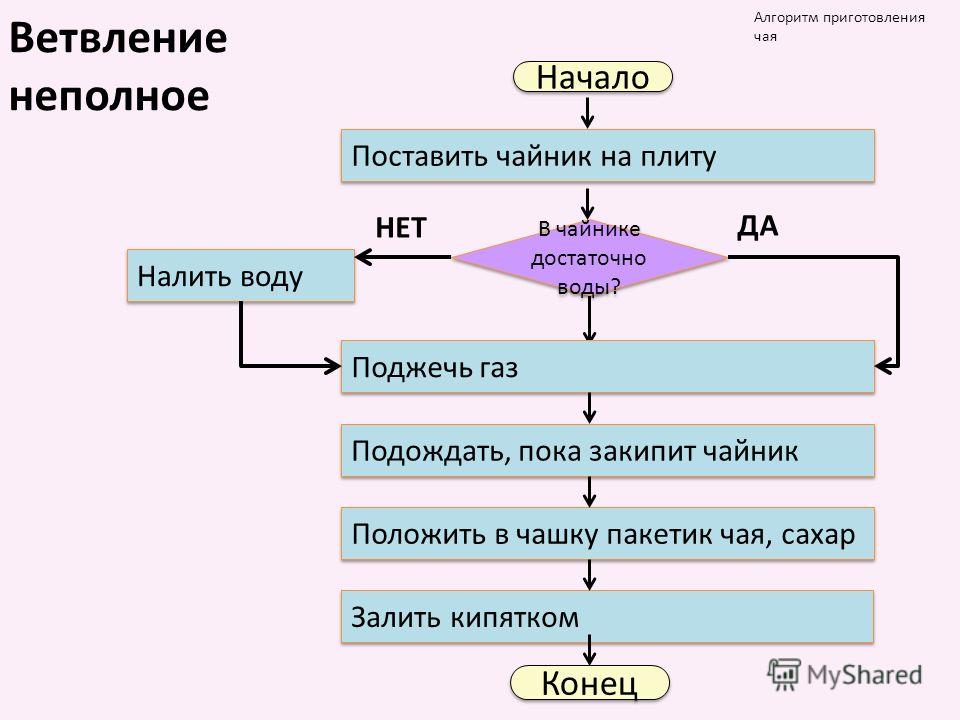
2,3. Изучение и первичное закрепление нового материала. Детальный план действий – это и есть алгоритм. Вот мы и подошли к теме нашего урока, к понятию «Алгоритм». Слово алгоритм происходит от имени математика IX века Аль-Хорезми, который сформулировал правила арифметических действий над числами. Откуда произошло слово Алгоритм: http://files. school-collection. edu. ru/dlrstore/88093ab9-6a3e-4bc6-8d5d-9b7434d8416b/9_31. swf Определение: Описание последовательности действий, строгое исполнение которых приведёт к задуманному результату, называется алгоритмом. Очень важно запомнить!
Алгоритмы полезно составлять, т. е. очень важно научиться мыслить алгоритмически. Алгоритмическое мышление поможет человеку научиться размышлять, анализировать, планировать свои действия, отчетливо увидеть шаги, ведущие к цели. Алгоритмы окружают нас повсюду. Это и алгоритм приготовления блюда, и алгоритм пошива одежды, и инструкция по использованию стиральной машины или музыкального центра и т. д. Приведите свои примеры, где в вашей жизни вы встречаетесь с алгоритмами? Задание №1: Расставь пропущенные команды в алгоритме для робота: http://files. Задание №2: Посмотри мультфильм и расставь команды в алгоритме: Завари чай: http://files. school-collection. edu. ru/dlrstore/854022c0-136c-4ca9-a2f6-a257f11080b7/%5BNS-INF_2-02-06-08%5D_%5BIM_101%5D. swf | Учащиеся приводят примеры. Учащиеся выполняют задание на компьютере Учащиеся выполняют задание на компьютере |
| Как вы считаете, любую ли последовательность действий можно считать алгоритмом? Нет! Алгоритм должен удовлетворять ряду свойств. Каких же? Рассмотрим примеры. 1) Как вы считаете, будет известное вам явление «круговорот воды в природе» алгоритмом? 2) Можно ли данную последовательность действий считать алгоритмом? – Достать ключ – Вставить его в замочную скважину – Повернуть ключ 2 раза против часовой стрелки – Вынуть ключ – Открыть дверь. 3) В одной из русских народных сказок герою дается поручение «Пойди туда, не знаю куда, принеси то, не знаю что». Можно ли этот набор действий считать алгоритмом? Как вы думаете, кто может быть исполнителем алгоритмов? Исполнители алгоритмов: http://files. school-collection. edu. ru/dlrstore/58e9a0c3-11df-4c94-a5eb-b0a7b359ea35/9_32. swf Итак, исполнитель – это что-то или кто-то, способный выполнить действия, предписываемые алгоритмом. Назовите исполнителей следующих видов работы: а) приготовление торта; б) пошив одежды; в) ремонт обуви; г) пломбирование зуба; д) уборка мусора во дворе. 4. Физкультминутка (музыкальное сопровождение) Как вы поняли, каждый алгоритм должен быть понятен исполнителю, поэтому алгоритм должен быть записан на понятном для исполнителя языке, и эта запись называется программой. Запишем: Итак, мы выяснили, что такое алгоритм и его исполнитель. Ребята, а сейчас мы немного поиграем: Задание №3: Исполнитель умеет, заменять в слове ровно одну букву на любую другую, причем при замене должно получиться осмысленное слово. Составьте алгоритм для преобразования слова САД в слово КОТ. Давайте теперь подумаем, какими свойствами обладает алгоритм. Свойства алгоритма: http://files. school-collection. edu. ru/dlrstore/ef6533fd-06d1-4b38-9498-ac58430f845e/9_33. swf – Дискретность – процесс решения задачи должен быт разбит на последовательность отдельных шагов. – Понятность. Алгоритм должен быть понятен исполнитель и исполнитель должен быть в состоянии выполнить его команды. – Определенность. Алгоритм не должен содержать команды, смысл которой может восприниматься неоднозначно. – Результативность. Процесс решения задачи должен прекратиться за конечное число шагов и при этом должен быть получен ответ задачи. – Массовость. По одному алгоритму можно решать однотипные задачи. Задание №4:Помоги Красной Шапочке добраться до бабушки. Запиши на языке стрелок алгоритм движения Красной Шапочки. Задание №5: Прочитай и подчеркни , что умеет делать робот: Знают дети всего мира: Робот, умная машина. Может он решать задачи, Может он стихи писать. Может робот печь печенье, И варить может варение, Может делать он детали, Может песни сочинять. | Нет (Нет, т. к. отсутствует свойство конечности). (Да, по определению) (Нет, т. к. отсутствуют все свойства алгоритма). технические устройства, человек, группа людей, дрессированные животные повар-кондитер швея мастер по ремонту обуви стоматолог уборщик территории Программа – запись алгоритма на языке исполнителя. Заменять в слове одну букву на другую, причем при замене должно получиться осмысленное слово. |
| 5. Подведение итогов урока: Ответьте, пожалуйста, следующие вопросы: – Что же такое алгоритм? – Приведите примеры алгоритмов, с которыми вы сталкиваетесь в жизни. А теперь попробуем ответить на вопрос: «Что означают слова: мыслить алгоритмически?» Итак, ребята, сегодня на уроке, вы увидели, что для лучшего усвоения, запоминания материала, необходимо составлять алгоритм ее решения, т. к. алгоритмы: 1. Развивают четкость и ясность мышления. 2. Развивают внимательность, аккуратность 3. Способствуют формированию алгоритмического стиля мышления. Домашнее задание: повторить изученный материал на уроке, подготовить алгоритмы , связанные с жизнью и деятельностью человека, его бытом, разгадать кроссворд Молодцы! Спасибо за урок. До свидания. | Описание последовательности действий, строгое исполнение которых приведёт к задуманному результату, называется алгоритмом. Учащиеся приводят примеры: переход через дорогу, решение некоторых задач по математике, бутерброд, учебный процесс с 1 по 11 класс. . . Для решения любой задачи необходимо составить план ее решения, анализировать получаемые результаты, предусматривать различные варианты решения и т. д. |
 school-collection. edu. ru/dlrstore/e5fdb511-4a83-4865-a2a8-90292a4dfcad/%5BNS-INF_3-01-01-02%5D_%5BIM_153%5D. swf
school-collection. edu. ru/dlrstore/e5fdb511-4a83-4865-a2a8-90292a4dfcad/%5BNS-INF_3-01-01-02%5D_%5BIM_153%5D. swf

 САД – САМ – СОМ – КОМ – КОТ
САД – САМ – СОМ – КОМ – КОТЕ. В. Филюшина, ГБОУ СОШ № 339, Санкт-Петербург
Метки: Информатика
(курс 68 ч.) Алгоритм и его формальное исполнение
Планирование уроков на учебный год (по учебнику Н.Д. Угриновича)
Главная | Информатика и информационно-коммуникационные технологии | Планирование уроков и материалы к урокам | 9 классы | Планирование уроков на учебный год (по учебнику Н.Д. Угриновича) | Алгоритм и его формальное исполнение
Содержание урока
1.1.1. Свойства алгоритма и его исполнители
1.1.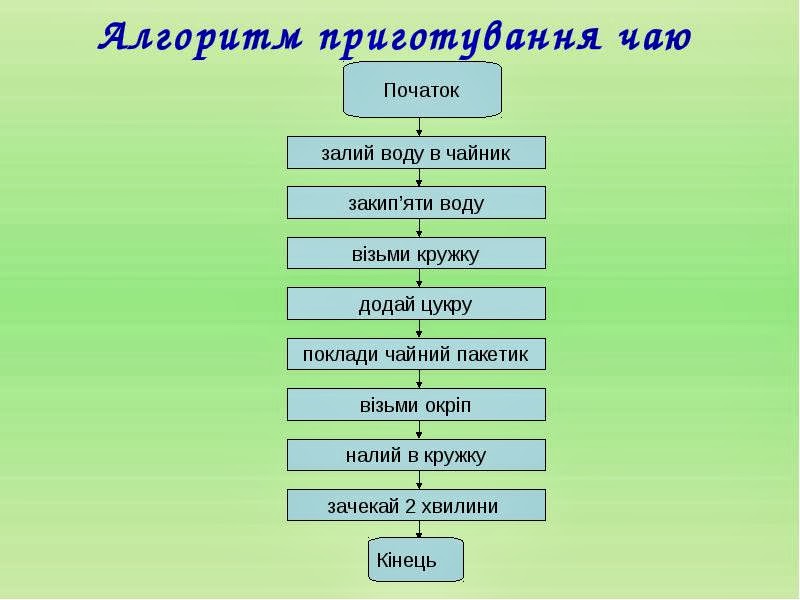 2. Выполнение алгоритмов компьютером
2. Выполнение алгоритмов компьютером
1.1.3. Основы объектно-ориентированного визуального программирования
Лабораторная работа № 1
Лабораторная работа № 3. Шаг 1
Лабораторная работа № 3. Шаг 2. Задача 1
Лабораторная работа № 3. Шаг 2. Задача 2
Лабораторная работа № 3. Шаг 2. Задачи 3 и 4
Лабораторная работа № 3. Шаг 3
1.1.1. Свойства алгоритма и его исполнители
Дискретность. Во многих отраслях человеческой деятельности для достижения требуемого результата используются алгоритмы, содержащие четкие описания последовательности действий. Примерами алгоритмов являются кулинарные рецепты, в которых подробно описана последовательность действий по приготовлению пищи.
Алгоритмы кулинарных рецептов состоят из отдельных действий, которые обычно нумеруются. Разделение алгоритма на последовательность шагов является важным свойством алгоритма и называется дискретностью.
Алгоритм приготовления блюда быстрого питания:
1. Высыпать в емкость содержимое пакетика.
2. Налить в емкость 200 мл горячей воды.
3. Тщательно перемешать.
Результативность. Алгоритмами являются известные из начальной школы правила сложения, вычитания, умножения и деления столбиком. Применение этих алгоритмов независимо от количества разрядов в числах и, соответственно, количества вычислительных шагов алгоритма всегда приводит к результату. Получение из исходных данных результата за конечное число шагов называется результативностью алгоритма.
Алгоритм сложения целых чисел в десятичной системе счисления:
1. Записать числа в столбик так, чтобы цифры самого младшего разряда чисел (единицы) расположились одна под другой (на одной вертикали).
2. Сложить цифры младшего разряда.
3. Записать результат под горизонтальной чертой на вертикали единиц, если при этом полученная сумма больше или равна величине основания системы счисления (в данном случае 10), перенести десятки в старший разряд десятков.
4. Повторить пункты 2 и 3 для всех разрядов с учетом переносов из младших разрядов.
Массовость. Алгоритмы сложения, вычитания, умножения и деления могут быть применены для любых чисел, причем не только в десятичной, но и в других позиционных системах счисления (двоичной, восьмеричной, шестнадцатеричной и др.). Возможность применения алгоритма к большому количеству различных исходных данных называется массовостью.
Само слово «алгоритм» происходит от «algorithmi» — латинской формы написания имени выдающегося математика IX века аль-Хорезми, который сформулировал правила выполнения арифметических операций.
Исполнители алгоритмов. Алгоритмы широко используются в технике в системах управления объектами. В любой системе управления существует управляющий объект, который является исполнителем алгоритма управления. Так, в системах терморегуляции для поддержания определенной температуры в помещении исполнителем алгоритма может являться как человек, так и микропроцессор.
Алгоритм терморегуляции:
1. Измерить температуру в помещении.
2. Если измеренная температура ниже заданной, включить обогреватель.
Детерминированность (определенность). При управлении самолетом используются сложные алгоритмы, исполнителями которых являются пилот или бортовой компьютер. При этом важно, чтобы каждая команда определяла однозначное действие исполнителя. Кроме того, последовательность выполнения действий, например, при взлете должна быть строго определенной (например, нельзя отрываться от взлетной полосы, пока самолет не набрал необходимую взлетную скорость). Исполнитель алгоритма, выполнив очередную команду, должен точно знать, какую команду необходимо исполнять следующей.
Понятность. После включения компьютера начинают выполняться алгоритмы тестирования компьютера и загрузки операционной системы. Исполнителем этих алгоритмов является компьютер, поэтому они должны быть записаны на понятном компьютеру машинном языке.
Каждый исполнитель обладает определенным набором, системой команд, которые он может выполнить. Алгоритм должен быть понятен исполнителю, т. е. должен содержать только те команды, которые входят в систему команд исполнителя.
Свойства алгоритма. Выше были приведены примеры алгоритмов из различных областей человеческой деятельности и знаний. В этих алгоритмах различные исполнители выполняли операции над объектами различной природы (материальными объектами и числами). При этом во всех примерах можно выделить следующие основные свойства алгоритма:
Результативность и дискретность. Алгоритм должен обеспечивать получение из исходных данных результата за конечное число дискретных шагов.
Массовость. Один и тот же алгоритм может применяться к большому количеству однотипных объектов.
Детерминированность (определенность). Исполнитель должен выполнять команды алгоритма в строго определенной последовательности .
Понятность. Алгоритм должен содержать команды, входящие в систему команд исполнителя и записанные на понятном исполнителю языке.
Алгоритм — это описание детерминированной последовательности действий, направленных на получение из исходных данных результата за конечное число дискретных шагов с помощью понятных исполнителю команд.
Формальное исполнение алгоритма. Из приведенных выше свойств алгоритма вытекает возможность его формального выполнения. Это означает, что алгоритм можно выполнять, не вникая в содержание поставленной задачи, а только строго выполняя последовательность действий, описанных в алгоритме.
Контрольные вопросы
1. Приведите примеры известных вам алгоритмов.
2. Перечислите основные свойства алгоритмов и проиллюстрируйте их примерами.
3. Как вы понимаете формальное исполнение алгоритма?
Задания для самостоятельного выполнения
1. 1. Задание с развернутым ответом. Запишите алгоритм вычитания столбиком целых чисел в десятичной системе счисления.
1. Задание с развернутым ответом. Запишите алгоритм вычитания столбиком целых чисел в десятичной системе счисления.
Контрольные вопросы
1. Перечислите основные элементы блок-схем и их назначение.
Cкачать материалы урока
Глубокая технология, стоящая за оценкой времени приготовления пищи | от Зомато | Zomato Technology
By Deepankar Pal
Этот пост был первоначально опубликован в блоге Zomato 4 февраля 2020 года. немедленно? Почему лапша быстрого приготовления, растворимый кофе или готовые к употреблению упакованные продукты находят место на наших кухнях?
Мы просто ненавидим ждать. Мы считаем, что то же самое относится и к еде. Пара вопросов, которые всегда возникают у нас в голове: «Где моя еда?» или «Когда моя еда будет доставлена?» 9.0003
Для Zomato, с момента, когда клиент открывает приложение и до тех пор, пока его еда не будет доставлена к его порогу, нам важно предоставить точную информацию о том, когда его еда будет доставлена. Предоставление более высокой, чем фактическая, оценки времени может удержать клиентов от заказа, как и оценка времени доставки ниже фактического, что может увеличить приток клиентов в нашу службу поддержки.
Предоставление более высокой, чем фактическая, оценки времени может удержать клиентов от заказа, как и оценка времени доставки ниже фактического, что может увеличить приток клиентов в нашу службу поддержки.
Таким образом, точная оценка времени не только улучшает качество обслуживания клиентов, но и снижает нагрузку на нашу службу поддержки клиентов.
Как показано выше, в экосистеме доставки еды после того, как клиент размещает заказ, происходит несколько рукопожатий.
Каждый из этих шагов имеет связанный с ним компонент времени, т. е. время, которое потребуется ресторану для приготовления еды (время приготовления пищи, FPT), время, которое потребуется нашему партнеру по доставке (DP), чтобы достичь ресторан (время получения DP) и время, которое потребуется нашему DP, чтобы добраться до адреса клиента (время доставки DP).
Все это, а также несколько других компонентов времени (предсказуемых и непредсказуемых) объединяются, чтобы окончательно рассчитать время от размещения заказа до окончательной доставки, которое затем демонстрируется нашим клиентам.
Онлайн-платформа доставки еды Zomato имеет рестораны в более чем 500 городах Индии с более чем 400 кухнями, что ясно говорит нам о том, что разнообразие можно найти в каждом уголке этой страны.
Масштабы бизнеса требуют более точного прогнозирования FPT, что, в свою очередь, помогает сократить время доставки, лучше распределить DP при назначении заказов и повысить эффективность доставки заказов. Это также помогает нам лучше взаимодействовать с нашими партнерами-ресторанами для отслеживания нарушений FPT и соблюдения требований.
Существует множество факторов, влияющих на FPT для конкретного блюда. Скажем, клиент заказывает бирьяни с курицей (D1) в двух ресторанах (R1 и R2) —
- R1 — ресторан, который специализируется на приготовлении бирьяни.
- R2 — это ресторан с разнообразной кухней, в котором наряду с другими блюдами используется бирьяни.
При прочих равных сценариях можно ожидать, что FPT куриного бирьяни от R1 будет меньше, чем у R2, поскольку –
- R1 специализируется на бирьяни, и ожидается, что их кухня, а также приготовление пищи будут приспособлены к приготовлению бирьяни. Кроме того, они могли бы оптимизировать свой процесс для минимального времени приготовления бирьяни.
- R2 обслуживает широкий спектр блюд, и, вероятно, не будет процессов, оптимизированных для конкретного продукта, поскольку одна и та же кухня используется для приготовления нескольких блюд.
 Кроме того, они могли бы оптимизировать свой процесс для минимального времени приготовления бирьяни.
Кроме того, они могли бы оптимизировать свой процесс для минимального времени приготовления бирьяни.Но здесь могут быть определенные дополнительные факторы —
- Заказы в очереди — это количество заказов, уже находящихся в очереди для каждого ресторана. Возможно, в одном ресторане длинная очередь, а в другом нет активных заказов.
- Рестораны высокой кухни и кухни доставки — если один ресторан является заведением высокой кухни, а другой — кухней доставки, ожидается, что последний будет иметь более короткий FPT.
- Часы работы — это относится к периоду, на который ресторан был открыт для доставки. Он открылся только сейчас или давно открыт? Это мягкие параметры, которые передают, кипит ли кухня или нет.
- Другие позиции в заказе — Помимо куриного бирьяни, какие еще позиции в заказе? Могут ли элементы готовиться параллельно, или они будут готовиться последовательно, или эти отдельные элементы имеют более высокую или более низкую FPT?
Нужно помнить о многих компонентах!
Учитывая характер проблемы, мы разделили ее на два основных компонента –
Информация об уровне позиции , т. е. номенклатурный состав заказа
е. номенклатурный состав заказа
- Как предполагалось ранее, разные номенклатуры будут иметь разное время подготовки.
- Заказы большего количества могут занять немного больше времени.
Информация об уровне ресторана , то есть неотъемлемые характеристики и характер ресторана в отношении времени приготовления пищи
- Рестораны быстрого питания или службы доставки будут вести себя иначе, чем рестораны изысканной кухни.
- Вместимость кухни каждого ресторана может различаться.
Мы заметили, что информация уровня элемента обычно представлена в текстовом формате. Чтобы использовать текстовую информацию в моделях машинного обучения, наиболее распространенными методами являются Bag-of-Words, Tf-Idf или Word2Vec Embedding . Первые два метода терпят неудачу в нашем масштабе, потому что они кодируют информацию в One Hot Encoding (это метод, при котором данные преобразуются в формы, которые помогают лучше прогнозировать). Учитывая, что определенное количество блюд на нашей платформе составляет ~ 3,5 млн, это привело бы к тому, что к нашим данным были бы добавлены миллионы столбцов. По той же причине используется Tf-Idf.
Учитывая, что определенное количество блюд на нашей платформе составляет ~ 3,5 млн, это привело бы к тому, что к нашим данным были бы добавлены миллионы столбцов. По той же причине используется Tf-Idf.
Мы отказались от этих двух подходов, потому что –
- Данные постоянно увеличиваются с увеличением количества блюд (каждый день на нашу платформу добавляется все больше новых блюд).
- Высокая размерность — потребуется много места для хранения и могут возникнуть проблемы с задержкой во время обслуживания модели.
- Последующие модели машинного обучения имеют проблемы с разреженностью, поэтому модели будут менее надежными.
Для нас встраивание Word2Vec стало предпочтительным выбором, потому что –
- Это позволило нам разместить информацию об уровне предмета в меньшем объеме памяти.
- Позволяет модели изучить поведение похожих предметов с точки зрения кухни и стиля приготовления.
Изображение выше представляет собой визуализацию и последующую кластеризацию векторов пунктов меню, обученных с использованием Word2Vec .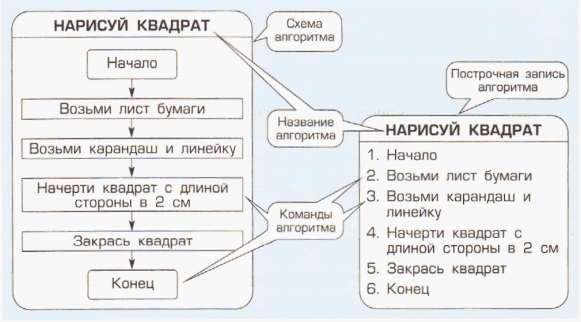 Можно видеть, как формируются различные кластеры. Например, все виды бирьяни вместе, но далеки от молочных коктейлей, что ожидаемо, так как это принципиально разные блюда.
Можно видеть, как формируются различные кластеры. Например, все виды бирьяни вместе, но далеки от молочных коктейлей, что ожидаемо, так как это принципиально разные блюда.
Заказ редко содержит только один элемент. В таком сценарии мы берем средневзвешенное количество и стоимость вектора элемента, чтобы получить окончательное представление меню. Ниже показано –
. Возьмем, к примеру, заказ, содержащий N предметов.
Окончательное представление заказа представляет собой средневзвешенное значение стоимости каждой позиции и заказанного количества.
Учитывая, что в месяц еду заказывают примерно из 150 000 ресторанов, понимание того, как ресторан может быть представлен численно для модели машинного обучения, становится наиболее важной частью этой головоломки.
В нашем случае ресторан представлен категориальными данными. Категориальные данные очень распространены в наборах бизнес-данных. Например, пользователи обычно описываются по стране, полу, возрастным группам и т.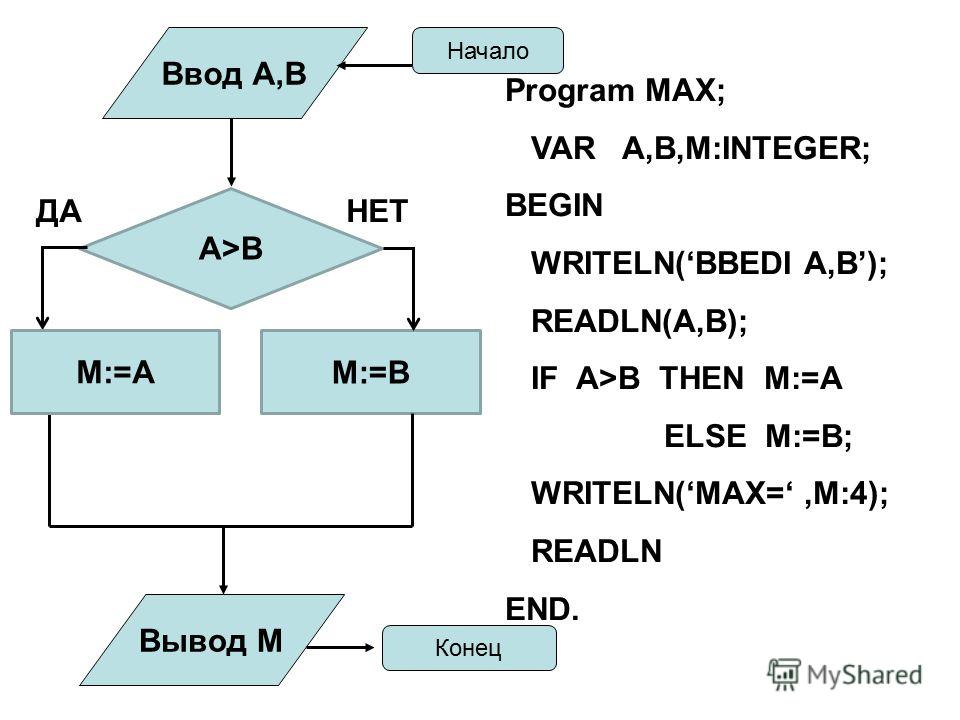 д. Продукты часто описываются по типу продукта, производителю, продавцу и т. д. Категории как метки кластера.
д. Продукты часто описываются по типу продукта, производителю, продавцу и т. д. Категории как метки кластера.
Категориальные данные чрезвычайно удобны для понимания, но очень сложны для большинства алгоритмов машинного обучения по этим причинам –
- Высокая кардинальность — категориальные переменные могут иметь большое количество уровней (например, город или рестораны), где большинство уровней появляются в относительно небольшом количестве экземпляров.
- Многие модели машинного обучения (например, SVM) являются алгебраическими, поэтому их ввод должен быть числовым. Используя эти модели, категории должны быть сначала преобразованы в числа, прежде чем мы сможем применить алгоритм обучения.
Основная предпосылка заключается в том, что мы позволяем нейронной сети самостоятельно вычислять наилучшее представление ресторана. Встраивание сущности — это векторное (список действительных чисел) представление сущности, в данном случае — ресторана.
Изображение выше представляет собой график T-SNE (обычно используемый для визуализации многомерных данных) самых популярных ресторанов в Бангалоре, где рестораны, предлагающие схожие кухни и блюда, объединены вместе.
X = {Текущая информация об уровне заказа, вектор заказа, вектор ресторана}
Y = время приготовления пищи
Мы инициализируем матрицу вложения, представляющую каждый ресторан с размерами «m». Каждый столбец матрицы вложения представляет один ресторан. Затем, используя различные функции, связанные с заказом, X-Vector передается через нейронную сеть. Благодаря обратному распространению представления ресторана обновляются с каждой итерацией вместе с весами.
Дополнительные сведения о категориальном встраивании.
XGBoost
Через матрицу внедрения мы получаем окончательное представление ресторана, а затем передаем тот же X-вектор, что и в архитектуре внедрения объекта, в модель регрессора XGBoost.
Архитектура глубокого обучения
Архитектура нашей предыдущей модели не могла учитывать предыдущие последовательности заказов, пришедших в ресторан; как выполненные заказы, так и текущие текущие заказы.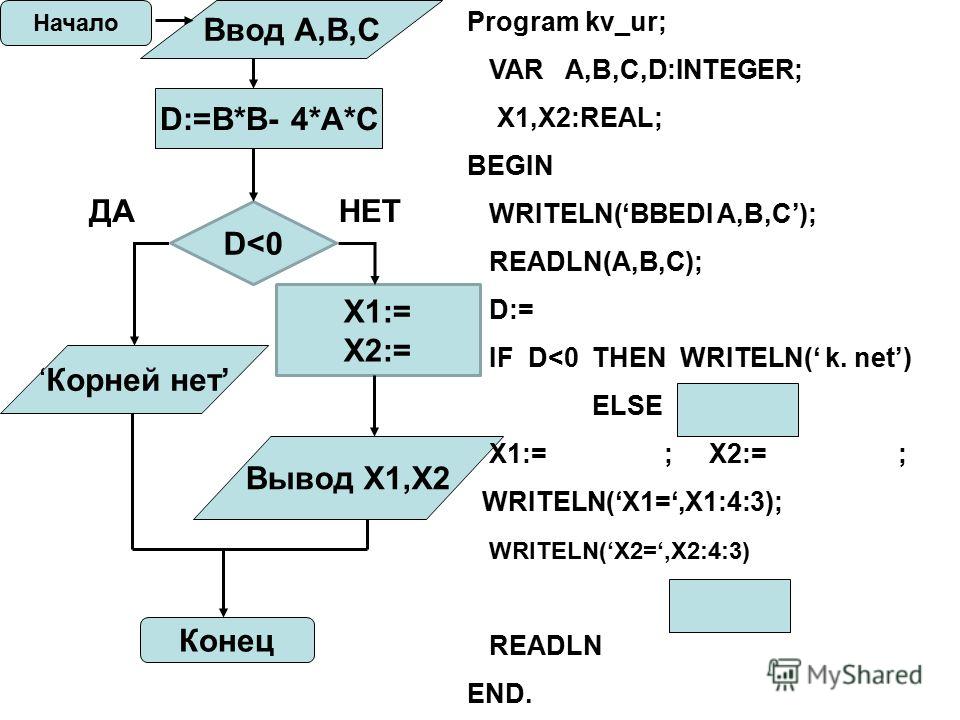
Можно ожидать, что если в «ранее выполненных заказах» был заказ Butter Chicken, то последующее прогнозирование FPT заказа Butter Chicken должно быть близко к прошлому значению. Последовательная передача информации позволит лучше понять вместимость и поведение кухни в моменты времени t . ТФП ресторана также можно понимать как временной ряд с различными амплитудами ряда (обозначающими ТФП заказа) в зависимости от приготавливаемого блюда. Следовательно, мы сузились до использования последовательной архитектуры, чтобы лучше представить кухню ресторана.
Как текущие заказы (текущие заказы во время T, максимум 5 текущих заказов), так и выполненные заказы (последние 5 выполненных заказов) проходят через сложенный слой LSTM. Результирующий вектор-столбец объединяется с функциями текущего заказа и вектором встраивания ресторана.
Результирующий вектор-столбец проходит через двухслойную плотную сеть и регрессирует на FPT.
Благодаря этому мы смогли уменьшить нашу среднюю абсолютную ошибку с 4,64 до 4,13 минуты и среднеквадратичную ошибку с 32 до 28.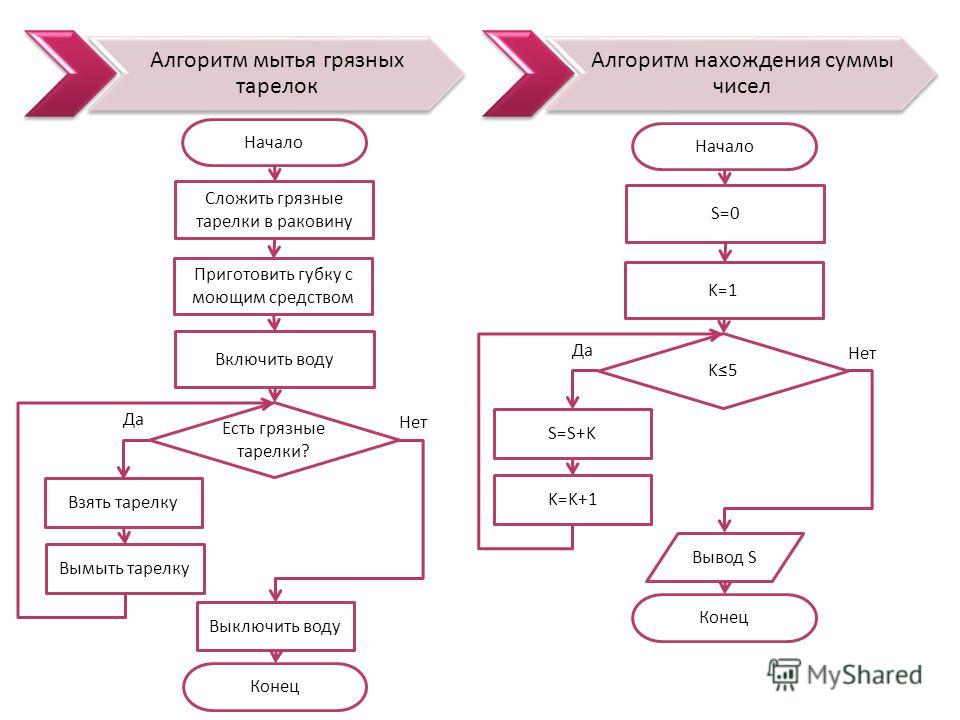
В дополнение к кодированию данных по ресторанам и блюдам, мы смогли дополнительно улучшить модель с помощью ввода информации о времени приготовления на уровне ресторана.
Ранее мы использовали для расчета FPT как разницу между временной меткой принятого рестораном заказа и временной меткой получения заказа DP. Это не привело к истинному FPT, поскольку поведение конкретного DP во время получения заказа стало частью уравнения. В идеале этого не должно быть, поскольку FPT — это ресторанный феномен. Чтобы исправить это, мы ввели кнопку «Готовность заказа еды» (FOR) в приложении Restaurant Partner.
Теперь они могут отмечать это каждый раз, когда продукты готовятся и готовы к выдаче. В наших первоначальных результатах мы увидели 9-процентное улучшение точности нашего прогноза в течение 5 минут. По мере увеличения соответствия FOR результаты наших прогнозов становятся еще более точными.
Мы также движемся к новейшей и самой захватывающей парадигме в мире науки о данных — обучению с подкреплением, то есть самообучающейся системе, которая обновляет веса в соответствии с ошибками в реальном времени, наблюдаемыми на уровне ресторана.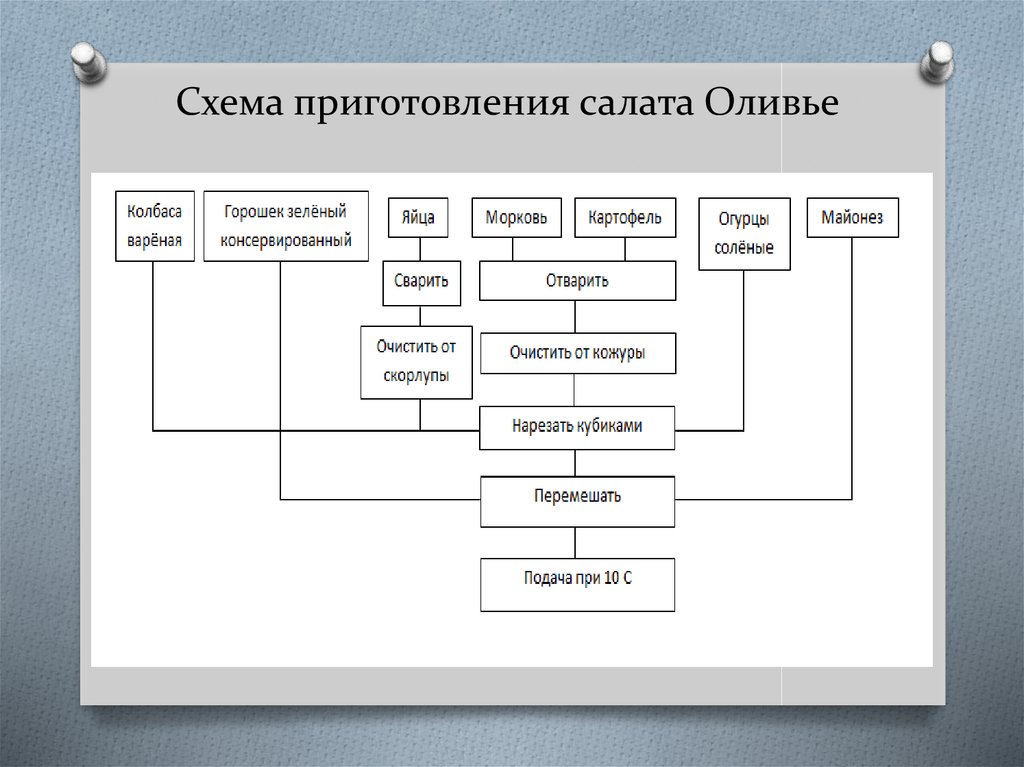
Учитывая, что время приготовления пищи представляет собой поведение в реальном времени, создание такой системы будет более элегантным решением этой проблемы, обеспечивая более плавное отслеживание заказов для наших клиентов.
машинное обучение, чтобы облегчить вопрос «что на ужин?» решение – блог Columbia University Postdoc Society
Когда д-р Яан Альтосар услышал, что лишение пищи увеличивает регенерацию стволовых клеток и активность иммунной системы у крыс, он сделал то, на что многие не осмелились бы: он решил попробовать сам и голодал пять дней. Мысли о еде начали завладевать его разумом, и, обладая сверхчеловеческой способностью мыслить при низком уровне сахара в крови, он пошел по касательной и направил их на решение сложной задачи по улучшению здоровья.0183 еда системы рекомендаций , что привело к публикации исследовательской статьи об этом.
Доктор Альтосар нуждался в помощи в принятии решений, потому что выбор труден. Столкнувшись с чрезмерным количеством вариантов, мы становимся жертвами усталости от принятия решений и склонны отдавать предпочтение привычным вещам.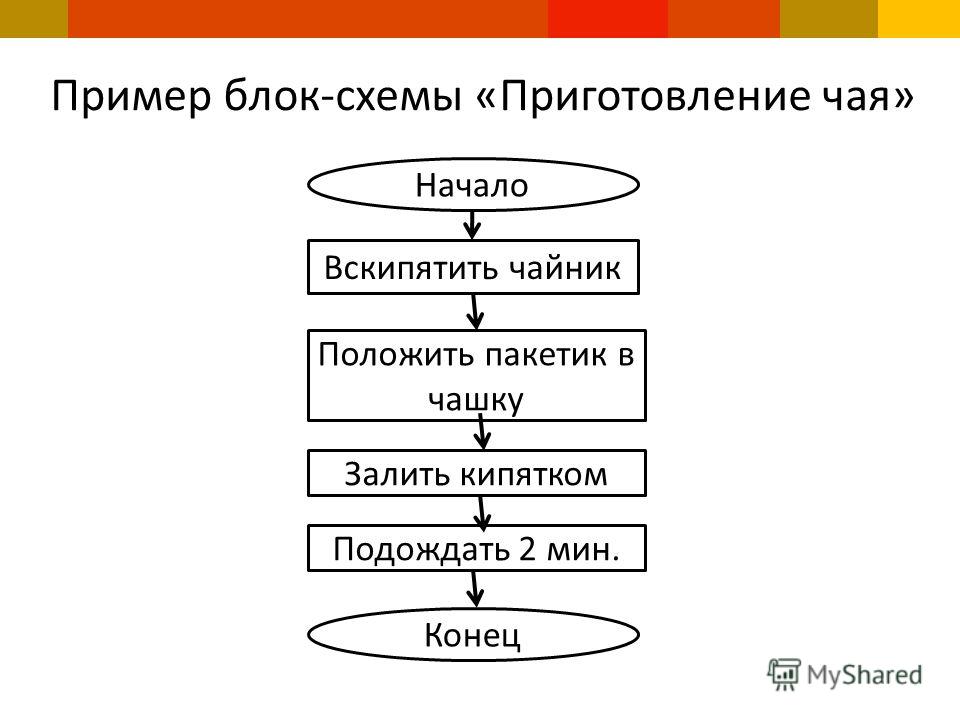 Компании знают об этом, и многие из них разработали персональные рекомендации для многих аспектов нашей жизни: посты Facebook в вашей хронике, потенциальные партнеры в приложениях для знакомств или предлагаемые продукты на Amazon. Но у Яана был явный фаворит: алгоритм Spotify Discover Weekly. Музыкальное приложение собирает информацию о совместном появлении исполнителей в плейлистах и сравнивает представление о вас как слушателе с парой миллиардов плейлистов, которыми оно располагает, чтобы предложить песни, которые могут вам понравиться. Поскольку проблема доктора Альтосара была похожей, он сформулировал ее как передачу алгоритму любимых рецептов пользователя («списков воспроизведения»), которые состоят из списка ингредиентов («песен»). Будет ли алгоритм предлагать бесплатные блюда на основе ингредиентов, содержащихся в них?
Компании знают об этом, и многие из них разработали персональные рекомендации для многих аспектов нашей жизни: посты Facebook в вашей хронике, потенциальные партнеры в приложениях для знакомств или предлагаемые продукты на Amazon. Но у Яана был явный фаворит: алгоритм Spotify Discover Weekly. Музыкальное приложение собирает информацию о совместном появлении исполнителей в плейлистах и сравнивает представление о вас как слушателе с парой миллиардов плейлистов, которыми оно располагает, чтобы предложить песни, которые могут вам понравиться. Поскольку проблема доктора Альтосара была похожей, он сформулировал ее как передачу алгоритму любимых рецептов пользователя («списков воспроизведения»), которые состоят из списка ингредиентов («песен»). Будет ли алгоритм предлагать бесплатные блюда на основе ингредиентов, содержащихся в них?
Еда, потребляемая пользователем (гамбургер), состоит из ингредиентов (хлеб, салат, помидоры, сыр, мясо). Эта информация передается алгоритму машинного обучения, который будет использовать полученную информацию об этом пользователе, чтобы предоставить рекомендацию, которая, вероятно, будет им съедена.
Рекомендации по питанию в приложении сложны по нескольким направлениям. Во-первых, приложение для отслеживания еды может регистрировать употребление одного и того же блюда разными способами или с уникальными вариациями (например, бутерброд с домашним острым соусом или без солений). Это означает, что любой конкретный прием пищи обычно регистрируется только небольшим числом пользователей. Кроме того, база данных всех возможных блюд, которые может отслеживать пользователь, огромна, и каждое блюдо содержит всего несколько ингредиентов.
В традиционных рекомендательных системах, таких как те, что используются Netflix, для решения этой проблемы может потребоваться сначала преобразовать данные в большую матрицу, где пользователи — это строки, а элементы (например, фильмы или еда) — столбцы. Значения в матрице — единицы или нуля в зависимости от того, потреблял ли пользователь элемент или нет. Современные версии рекомендательных систем, в том числе та, что описана в статье доктора Альтосара, также включают атрибуты товара (состав, доступность, популярность) и используют их в качестве дополнительной информации для более точного подбора рекомендаций. Однако нерешенной проблемой является достижение баланса между гибкость , чтобы учесть тот факт, что мы не все похожи на Джоуи Триббиани и можем не любить заварной крем, джем и говядину вместе взятые (даже если мы любим их по отдельности), и масштабируемость , поскольку увеличение количества атрибутов требует затраты времени на вычисления. Кроме того, эти алгоритмы машинного обучения не всегда обучаются так же, как позже оцениваются их производительность.
Однако нерешенной проблемой является достижение баланса между гибкость , чтобы учесть тот факт, что мы не все похожи на Джоуи Триббиани и можем не любить заварной крем, джем и говядину вместе взятые (даже если мы любим их по отдельности), и масштабируемость , поскольку увеличение количества атрибутов требует затраты времени на вычисления. Кроме того, эти алгоритмы машинного обучения не всегда обучаются так же, как позже оцениваются их производительность.
Разреженная матрица, показывающая, потреблял ли пользователь «u» элемент «m» (кодируется единицей). Если пользователь не потреблял элемент, это ноль. Обратите внимание, что большинство элементов в матрице нулевые, так что фактической информации не так много (поэтому ее называют разреженной).
Новый тип модели, предложенный доктором Альтосааром и его коллегами, RankFromSets , определяет проблему как бинарную классификацию. Это означает, что он учится присваивать ноль блюдам, которые вряд ли будут потребляться пользователем, и один тем, которые, вероятно, будут потребляться. Столкнувшись с тем, что пользователю предлагается набор возможных приемов пищи (скажем, пять), он стремится максимизировать количество приемов пищи, которые пользователь фактически съест из тех пяти, которые ему рекомендованы. Чтобы использовать возможности включения ингредиентов еды, алгоритм использует технику обработки естественного языка для обучения вложения . Это способ сжатия данных, чтобы сохранить важную информацию, которая вам нужна для решения вашей проблемы; в этом случае изучение шаблонов полезно для прогнозирования того, какие ингредиенты склоняют чашу весов для того, чтобы кто-то съел еду. Это позволяет получить численное представление для каждого приема пищи на основе составляющих его продуктов и моделей потребления этих продуктов всеми пользователями.
Столкнувшись с тем, что пользователю предлагается набор возможных приемов пищи (скажем, пять), он стремится максимизировать количество приемов пищи, которые пользователь фактически съест из тех пяти, которые ему рекомендованы. Чтобы использовать возможности включения ингредиентов еды, алгоритм использует технику обработки естественного языка для обучения вложения . Это способ сжатия данных, чтобы сохранить важную информацию, которая вам нужна для решения вашей проблемы; в этом случае изучение шаблонов полезно для прогнозирования того, какие ингредиенты склоняют чашу весов для того, чтобы кто-то съел еду. Это позволяет получить численное представление для каждого приема пищи на основе составляющих его продуктов и моделей потребления этих продуктов всеми пользователями.
Модель классификации RankFromSets включает несколько компонентов. Есть встраивания для представления пользовательских предпочтений вместе с вложениями, соответствующими еде, которую пользователь может потреблять . Классификатор приправлен дополнительной независимой от пользователя информацией о популярности еды и ее доступности . Эти компоненты используются моделью для определения вероятности того, что конкретная еда будет съедена пользователем. Потенциальные блюда, которые могут понравиться пользователю, или которые могут быть более полезными для здоровья, затем ранжируются, и пользователю рекомендуются лучшие блюда. Например, если вы употребляли авокадо в каждом приеме пищи, это сезон, и все эти миллениалы записывают свои тосты с авокадо, вы, скорее всего, будете получать рекомендации, включающие авокадо в будущем.
Классификатор приправлен дополнительной независимой от пользователя информацией о популярности еды и ее доступности . Эти компоненты используются моделью для определения вероятности того, что конкретная еда будет съедена пользователем. Потенциальные блюда, которые могут понравиться пользователю, или которые могут быть более полезными для здоровья, затем ранжируются, и пользователю рекомендуются лучшие блюда. Например, если вы употребляли авокадо в каждом приеме пищи, это сезон, и все эти миллениалы записывают свои тосты с авокадо, вы, скорее всего, будете получать рекомендации, включающие авокадо в будущем.
В качестве подтверждения концепции авторы протестировали свой метод не только на данных о еде, которые они получили из LoseIt! приложение для похудения, но и набор данных, не связанный с выбором еды. Для этого независимого набора данных авторы использовали варианты чтения и поведение пользователей arXiv, сервера препринтов. Они обучили модель на прошлых данных о поведении пользователей и оценили производительность (точность бумажных предложений) на ранее выделенной части тех же данных (таким образом, они знали, действительно ли пользователь читал статью, но эта информация была скрыта от алгоритма оценки). ). Это типичный способ оценки производительности систем машинного обучения, и их метод превзошел ранее разработанные рекомендательные системы. Лучшая производительность и возможность перевода на задачи, отличные от рекомендаций по приему пищи, свидетельствует о потенциале применения этого инструмента в других контекстах.
). Это типичный способ оценки производительности систем машинного обучения, и их метод превзошел ранее разработанные рекомендательные системы. Лучшая производительность и возможность перевода на задачи, отличные от рекомендаций по приему пищи, свидетельствует о потенциале применения этого инструмента в других контекстах.
Эта новая рекомендательная система может быть применена либо к приложениям с рекомендацией рецептов, либо даже к приложению, которое будет предлагать посетителям ресторана, впервые пришедшим в ресторан, пункты меню, которые им, скорее всего, понравятся, исходя из их предпочтений. Система также может включать дополнительную информацию помимо того, потреблял ли пользователь (и любил ли он) определенный ингредиент или блюдо. Иногда способ приготовления определяет, нравится еда или нет (брюссельская капуста, я смотрю на вас). Кроме того, классификация ингредиентов по вкусу также может помочь предложить аналогичные (и даже более здоровые) альтернативы. Таким образом, добавление этих тегов в качестве дополнительных слоев к пересечению между пользователем и едой, безусловно, обеспечит лучшие рекомендации и возможность готовить нестандартно. Пост доктора Альтосара мог, а мог и не повысить его стволовые клетки, но ему определенно удалось помочь всем остальным немного меньше беспокоиться о том, что сегодня на ужин.
Пост доктора Альтосара мог, а мог и не повысить его стволовые клетки, но ему определенно удалось помочь всем остальным немного меньше беспокоиться о том, что сегодня на ужин.
Д-р Яан Альтосар — научный сотрудник с докторской степенью в отделе биомедицинской информатики и активный участник CUPS. Он публикует потрясающий блог о машинном обучении и его последствиях.
Создание системы рекомендаций по питанию | Луис Рита
Машинное обучение для профилактики и лечения рака с помощью питания
На здоровье человека влияет множество факторов, таких как физические упражнения, сон, питание, наследственность и загрязнение окружающей среды. Поскольку питание является одним из важнейших изменяемых факторов в нашей жизни, небольшие изменения могут иметь большое значение. С экспоненциальным увеличением количества доступных вариантов питания уже невозможно учитывать их все. Единственный способ учесть предпочтения пользователей, максимизировать количество полезных для здоровья соединений и свести к минимуму нездоровые в пище — это использовать (3D) рекомендательные системы.
Целью этого проекта было использование самой большой общедоступной коллекции данных рецептов (Recipe1M+) для создания системы рекомендаций по ингредиентам и рецептам. Обучайте, оценивайте и тестируйте модель, способную предсказывать кухни по наборам ингредиентов. Оцените вероятность отрицательного взаимодействия рецепт-лекарство на основе предсказанной кухни. Наконец, создать веб-приложение как шаг вперед в построении системы 3D-рекомендаций.
Загрузите веб-приложение из репозитория GitHub и запустите его локально.
Известно множество факторов, влияющих на здоровье человека. Физические упражнения, сон, питание, наследственность, загрязнение окружающей среды и другие внешние факторы [1]. Поскольку питание является одним из важнейших изменяемых факторов в нашей жизни, неудивительно, что небольшие изменения могут привести к значительным результатам [2].
Имея сильные культурные связи с нашими диетами, можно выделить большое количество кухонь мира. Наиболее распространенные ингредиенты в каждом из них тесно связаны с характеристиками региона, такими как климат.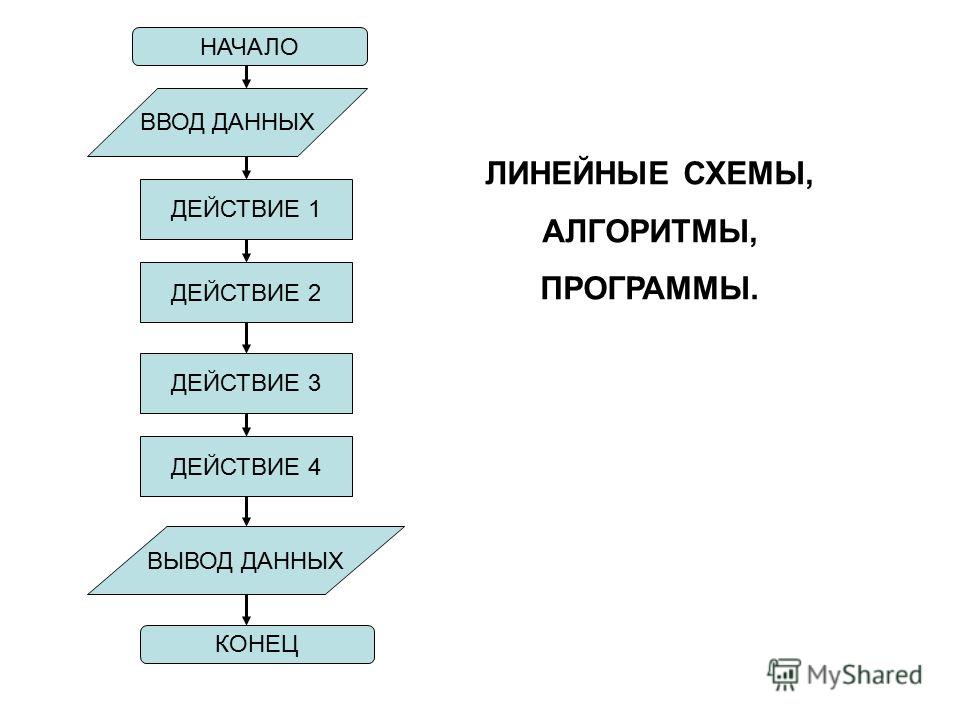 Это играет большое влияние на доступность каждого из компонентов, присутствующих в местных рецептах [3].
Это играет большое влияние на доступность каждого из компонентов, присутствующих в местных рецептах [3].
Известно, что некоторые молекулы положительно влияют на здоровье, а именно в борьбе с раком. Возможность определить, какие ингредиенты содержат более высокие концентрации, может помочь нам в лечении и профилактике заболевания [4]. Кроме того, включение этих ингредиентов во вкусные и доступные блюда может способствовать изменению пищевых привычек населения. В мире, где растет потребление фаст-фуда, очевидно, что помимо двух предыдущих пунктов важным фактором также является скорость приготовления [5].
По мере того, как все больше данных становятся доступными в Интернете, будь то исследования или веб-приложения, появляется возможность проанализировать их и создать новые системы рекомендаций по продуктам питания, которые не только учитывают такие факторы, как противораковые свойства, но также вкус, содержание питательных веществ и негативное взаимодействие с лекарствами. Это позволит пользователю принимать более взвешенные решения при покупке или приготовлении следующей еды [5].
Это позволит пользователю принимать более взвешенные решения при покупке или приготовлении следующей еды [5].
Рак
Болезнь XXI века (рис. 1). Принадлежа к более широкому спектру, называемому опухолями, рак представляет собой подтип, при котором происходит неконтролируемое деление клеток и может распространяться на разные ткани. Напротив, доброкачественные опухоли ограничены определенным органом. При наличии тесной корреляции между старением и утратой функции некоторых регуляторных путей по мере увеличения продолжительности жизни заболеваемость следует той же тенденции [6].
Известно, что питание может играть важную роль в профилактике и лечении этого заболевания [4]. Таким образом, было бы полезно максимизировать количество противораковых соединений в пище и свести к минимуму те, которые, как известно, отрицательно взаимодействуют с противоопухолевыми препаратами.
Рисунок 1 Основные причины смерти в мире, 2016 г. Рак занимает второе место в списке.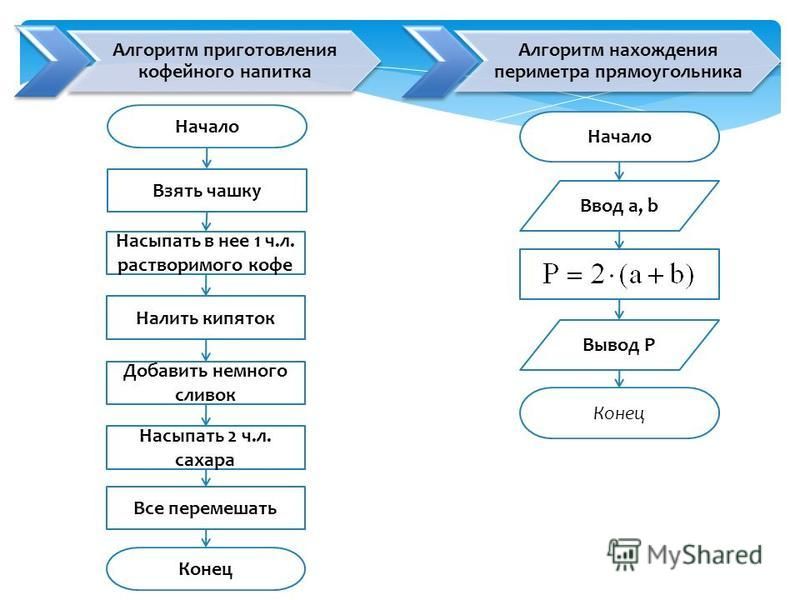 Адаптировано из [7].
Адаптировано из [7].
Обработка естественного языка
Хотя онлайн-наборы данных и API (интерфейс прикладного программирования) содержат структурированную информацию, которую можно легко извлечь, большинство онлайн-источников не имеют такой организованной структуры. Следовательно, необходимы алгоритмы, способные не только извлекать данные, но и получать их контекст [8]. В этом разделе основное внимание уделяется встраиванию слов и моделированию тем.
Существует несколько способов векторного представления слов. Одна из возможностей состоит в том, чтобы выровнять их все и представить каждый как вектор нулей и числа 1 в соответствующей позиции выравнивания. Тогда размеры векторного пространства будут равны размеру словаря. Хотя этот подход применим для небольших словарей, он неэффективен в вычислительном отношении. В качестве альтернативы существует другой механизм встраивания слов, который позволяет представлять большие словари с использованием низкоразмерных векторов с учетом контекста слова в предложении.
Разработанный группой исследователей во главе с Томасом Миколовым из Google, Word2Vec представляет собой неглубокую двухслойную нейронную сеть, предназначенную для конкретной категории моделей, которая производит встраивание слов [9]. Он принимает в качестве входных данных корпус текста и охватывает векторное пространство, где каждое слово отображается в вектор. Слова, которые чаще встречаются в схожих контекстах, отображаются в векторы, разделенные более короткими евклидовыми расстояниями.
Word2Vec — не единственный инструмент для тематического моделирования. Doc2Vec и FastText способны кодировать целые документы или смотреть конкретно на морфологическую структуру каждого слова соответственно [10].
Word2Vec был выбран для кодирования ингредиентов из наборов данных, используемых в этом проекте, в виде векторов. Это позволило выявить их сходство из их контекста в рецептах.
Обратный алгоритм приготовления
Этот алгоритм поиска рецепта был разработан Facebook AI Research и способен предсказывать ингредиенты, инструкции по приготовлению и название рецепта прямо из изображения [11].
В прошлом алгоритмы использовали простые системы поиска рецептов на основе сходства изображений в некотором пространстве встраивания. Этот подход сильно зависит от качества изученного встраивания, размера набора данных и изменчивости. Поэтому эти подходы терпят неудачу, когда нет соответствия между входным изображением и статическим набором данных [11].
Алгоритм обратного приготовления вместо извлечения рецепта непосредственно из изображения предлагает конвейер с промежуточным этапом, на котором сначала получается набор ингредиентов. Это позволяет генерировать инструкции с учетом не только изображения, но и ингредиентов (рис. 2) [11].
Рисунок 2 Обратная модель генерации рецепта приготовления с несколькими энкодерами и декодерами, генерирующими инструкции по приготовлению [11].
Одним из основных достижений этого метода было обеспечение более высокой точности, чем у базовой системы поиска рецептов [12] и среднего человека [11], при попытке предсказать ингредиенты по изображению.
Алгоритм Inverse Cooking был включен в систему рекомендаций по еде, разработанную в этом проекте. На основе предсказанных ингредиентов в веб-приложении пользователю предоставляется несколько предложений, например: различные комбинации ингредиентов.
Уменьшение размерности
Как правило, уменьшение размерности направлено на сохранение как можно большего количества информации из многомерных векторов. Анализ главных компонентов (PCA) [13] и T-распределенные стохастические соседние объекты (T-SNE) [14] являются двумя наиболее часто используемыми подходами. Первый обычно определяется как наличие математического подхода к проблеме, а второй — как статистический.
Основная цель PCA заключается в сохранении векторных компонентов с более высокой изменчивостью данных и отбрасывании тех, которые добавляют меньше информации. Это разложение может быть достигнуто двумя различными способами. Один из них заключается в разложении матрицы ковариации данных на ее собственные значения. Во-вторых, путем выполнения разложения матрицы данных по одному значению после нормализации исходных данных [13].
С другой стороны, T-SNE преобразует сходство между точками в совместные вероятности. И минимизирует расхождение Кульбака-Лейблера между этими вероятностями для низкоразмерного вложения и многомерных данных. Этот подход имеет функцию стоимости, которая не является выпуклой, следовательно, разные инициализации могут давать разные уменьшенные векторы размерности [14].
Способность визуализировать многомерные данные имеет решающее значение, особенно в ситуации заинтересованности в выполнении кластеризации. В зависимости от приложения алгоритмы поиска сообществ могут быть введены с различными пороговыми параметрами, которые влияют на размер и связность кластеров. Возможность визуализировать распределение данных позволяет использовать человеческое мышление при выборе этих значений.
Быстрое выполнение и надежные результаты сделали PCA лучшим выбором.
Находка сообщества
Существует множество алгоритмов кластеризации, оптимизирующих различные функции затрат.
Алгоритм Лувена итеративно разбивает сеть, оптимизируя модульность [15]. Его значение пропорционально количеству соединений между узлами внутри одного кластера и уменьшается, когда число межкластерных соединений начинает расти. Математически модульность определяется:
Aij — элемент матрицы смежности, представляющий вес ребер, соединяющих узлы i и j , ki = ∑j Aij — степень узла i , ci — сообщество, которому он принадлежит, 𝛿-функция 𝛿(u,v) равна 1, если u = v , и 0 в противном случае. m = 1/2*∑ij Aij — сумма весов всех ребер графа [15].
Между шагами итерации оптимизируемой величиной является ее изменение, что делает вычисления более эффективными [15]:
В то время как ki, в и ∑tot необходимо рассчитать для каждого пробного сообщества, ki/2m зависит от анализируемого узла. Таким образом, последнее выражение пересчитывается только тогда, когда при оптимизации модульности рассматривается другой узел [15].
Алгоритм Infomap пытается уменьшить длину описания сети за счет уменьшения воображаемого потока, который случайным образом распространяется внутри сети между идентифицированными кластерами [16]. Математически это можно выразить:
Быть q = ∑(m)(j=1) qj сумма вероятности выхода для каждого сообщества, H(Q) средняя длина кода движения между сообществами, p(i)(o )= qi + ∑(m)(β∈i) pβ вероятность пребывания при случайном блуждании в сообществе c и H(Pm) средняя длина кода модуля кодовой книги m [16].
Третий подход, также широко используемый, называется спектральной кластеризацией [17]. Он имеет ряд преимуществ перед двумя предыдущими. Наиболее важным является то, что он показывает более высокую точность обнаружения кластеров, которые сильно невыпуклы или когда мера центра и распространение кластера не являются подходящим описанием предсказанного сообщества. Более того, в отличие от двух других, его реализация на Python позволяет пользователю вводить количество желаемых кластеров, присутствующих в данных. Это был первый выбор для выполнения кластеризации в рамках проекта.
Визуализация данных
В Python есть несколько инструментов для визуализации данных. А именно, Matplotlib [18], Plotly [19], Seaborn [20] и Pandas [21]. Некоторые считаются более эффективными для представления больших объемов данных, другие известны своей универсальностью и позволяют пользователю легко визуализировать данные несколькими способами. Другие интегрированы с существующими контейнерами данных и в конечном итоге облегчают их визуализацию. Совместимость с самыми последними платформами для анализа и визуализации данных, такими как Jupyter Notebook или JupyterLab, также является важным критерием.
Matplotlib позволяет генерировать широкий спектр категорий, таких как: диаграммы рассеяния, диаграммы ошибок, гистограммы, спектры мощности, гистограммы и другие. Хотя они статичны, и когда количество узлов в случае диаграммы рассеяния превышает десятки тысяч, она больше не может их представлять [18].
Plotly отличается от Matplotlib возможностью динамического представления точек данных вместе с их метками. Он также лучше масштабируется, когда величина количества точек превышает десятки тысяч [19].].
Seaborn — это библиотека Python, построенная на базе Matplotlib. Он так же эффективен, как и последний, в представлении большого количества точек данных и позволяет пользователю более простым способом исследовать новые варианты визуализации [20].
Из-за отмеченных ранее моментов и того факта, что все они совместимы с JupyterLab (в случае с Plotly, после установки соответствующего расширения), эти 3 модуля использовались в проекте.
Системы рекомендаций по питанию
Хотя еда является основной потребностью, иногда люди не знают, что выбрать. На самом деле, при покупке еды или заказе через Интернет количество вариантов слишком велико, чтобы учесть их все.
Люди имеют разные потребности в питании и по-разному воспринимают вкус. По этой причине единственный способ удовлетворить их потребности — это узнать человека. Независимо от того, предназначена ли рекомендация для простого голодного пользователя, энтузиаста кулинарии, заботящегося о своем здоровье, сидящего на диете или для кого-то, кто болен и ищет улучшения своего медицинского статуса, это повлияет на окончательный выбор [5].
Более того, рекомендуемый продукт также имеет важное значение: простая замена ингредиентов, рецепт, блюдо, ресторан или даже кухня. Сроки рекомендации: в режиме реального времени или в виде рассылки. И он может учитывать местоположение пользователя и предлагать ближайшие места. Платформа, на которой вносятся предложения. В зависимости от того, как генерируются рекомендации (совместная фильтрация, на основе контента, кластеризация графиков или встраивания), они могут требовать от устройства разных функций. Таким образом, ими можно поделиться на веб-сайте, в приложении или в виде обычного текста (SMS). Наличие аллергенных или непереносимых соединений (таких как орехи и молоко), бренды, необходимое время для приготовления, курс, кухня, наличие продуктов животного происхождения, тип блюда, ингредиенты, стоимость, количество ингредиентов, время приготовления, вкус или методы требуется для приготовления пищи [5].
Важным фактором при построении этих систем является источник данных. Это могут быть прошлые заказы, реакция пользователя на определенную публикацию (нравится или не нравится), рейтинги, присвоенные сообществом, просмотренные изображения или видео или другие действия, связанные с социальной сетью, включая публикации, публикации, поиски, комментарии или подписчики [5].
Успех системы рекомендаций по питанию (рис. 3) связан с ее способностью учитывать предпочтения пользователей, максимизировать количество полезных для здоровья соединений и сводить к минимуму нездоровые в пище.
В рамках этого проекта были изучены различные подходы к составлению рекомендаций по питанию на основе общедоступных данных. Большие наборы данных рецептов (Recipe1M+ и Kaggle and Nature (K&N)), содержащие информацию о присутствующих ингредиентах, названиях, унифицированных указателях ресурсов (URL) источников и кухнях, были проанализированы для предоставления наиболее точных рекомендаций.
Рисунок 3 Пример системы рекомендаций по питанию [5].
Целью этого проекта было создание системы рекомендаций по продуктам питания для ингредиентов и рецептов. Это включало предварительную обработку набора данных Recipe1M+ для поиска ингредиентов. Оптимизировать словарь ингредиентов, чтобы они соответствовали тексту рецепта. Обучить модель Word2Vec, способную преобразовывать ингредиенты и рецепты в числовые векторы. Для визуализации ингредиентов в 2D-пространстве и использования их в качестве системы рекомендаций по ингредиентам. Обучить, оценить и протестировать модель классификатора опорных векторов (SVC), способную предсказать, к какой кухне принадлежит рецепт, учитывая набор ингредиентов. Предсказать вероятность отрицательного взаимодействия рецепт-лекарство на основе предсказанной кухни. Для определения кухонь по более высокому среднему количеству побеждающих рак молекул на рецепт. Наконец, создать веб-приложение, способное предсказывать ингредиенты по изображению, предлагать новые комбинации и извлекать кухню, которой принадлежит рецепт, а также оценивать ожидаемое количество негативных взаимодействий с противоопухолевыми препаратами.
Во введении обсуждались фундаментальные концепции, лежащие в основе рака, обработки естественного языка, обратного алгоритма приготовления пищи, уменьшения размерности, поиска сообщества, визуализации данных и систем рекомендаций по еде, доступных в Интернете. Методология детализирует цели проекта и знакомит с инструментами, используемыми для их решения. В разделе «Результаты» представлены и обсуждаются результаты проекта. Наконец, в Заключении напоминается цель проекта, обсуждается, были ли достигнуты цели, приводятся основные трудности и предложения для дальнейшей работы.
Введение охватывает широкий спектр теоретических концепций, в частности, инструменты, используемые в проекте. В методологии будет описано, как они были настроены и применены в соответствии с поставленными задачами. Также были включены наиболее важные пакеты Python и JavaScript, используемые на каждом этапе проекта.
Во-первых, наборы данных Recipe1M+ и K&N, а также словарь ингредиентов описываются с точки зрения их структуры и ценности для проекта. Также были включены процессы оптимизации, которые они представили.
Процесс встраивания ингредиентов в векторное пространство, уменьшения их размерности и кластеризации детализирован с точки зрения используемых инструментов и настройки параметров, выполненной с учетом характеристик предыдущих наборов данных.
Далее был объяснен классификатор, предсказывающий кухни из каждого набора рецептов ингредиентов, с учетом выбора параметров и функций с учетом размеров обучающего набора.
Затем был описан подход к классификации рецептов и кухонь в соответствии с количеством в них противораковых молекул и прогнозируемым количеством негативных взаимодействий рецепт-лекарство.
Определены инструменты визуализации данных, используемые для каждого графика.
Наконец, веб-приложение, которое извлекает ингредиенты из изображения рецепта и использует многие из систем рекомендаций по продуктам, разработанных в рамках этого проекта, представлено и подробно описано с точки зрения его реализации.
Набор данных Recipe1M+
Набор данных Recipe1M+ — это самый большой общедоступный набор данных рецептов [22]. Информация, содержащаяся в каждом рецепте, разделена на два файла нотации объектов JavaScript (JSON).
Первый идентифицирует каждый рецепт с помощью идентификатора и определяет ингредиенты, инструкции, заголовок, URL-адрес и набор, к которому он принадлежит: обучающий, подтверждающий или тестовый набор. Эти три группы использовались для обучения, проверки и тестирования алгоритма обратного приготовления. Второй файл включает в себя идентификаторы рецептов из первого и набор URL-адресов, указывающих на изображения с веб-сайтов, рецепты которых были удалены. Некоторые URL больше не активны. Хотя с помощью Wayback Machine (archive.org/web) можно получить доступ и визуализировать рецепты.
Вместе с этим набором данных были доступны два файла pickle, содержащие словарь ингредиентов и инструкции к рецептам.
Одним из необходимых шагов к созданию системы рекомендаций по еде было извлечение ингредиентов из текстов рецептов в наборе данных Recipe1M+. Для этого был оптимизирован словарь существующих ингредиентов, из которого были удалены все стоп-слова и знаки препинания, а оставшиеся слова лемматизированы.
После того, как набор данных Recipe1M+ был извлечен из общедоступных веб-сайтов, содержащих рецепты от его посетителей, ожидается наличие дезинформации, опечаток, нелатинских символов и прочего. Было подтверждено, например, что некоторые рецепты содержат ингредиенты или наборы инструкций, которые были пустыми или образованы исключительно последовательностями цифр или знаков препинания. Это было исправлено для всех этих случаев. Перед началом поиска ингредиентов из словаря в наборе данных все стоп-слова были удалены, а оставшиеся лемматизированы.
Набор данных Kaggle and Nature
Этот набор данных содержит несколько рецептов, помеченных кухнями, к которым они относятся (github.com/altosaar/food2vec/blob/master/dat/kaggle_and_nature.csv). Он использовался для обучения модели контролируемого обучения, способной предсказывать блюда из наборов ингредиентов. Те же ингредиенты, которые были идентифицированы с помощью словаря, описанного в предыдущем разделе.
Он структурирован как файл, разделенный запятыми, где каждая строка содержит отдельный рецепт. Первая ценность – это кухня рецепта. Остальные ингредиенты токенизированы. По этой причине для их извлечения не требовалось использование какого-либо словаря.
Чтобы максимально совпасть обозначения ингредиентов в этом наборе данных с обозначениями из Recipe1M+, все они были лемматизированы, а стоп-слова удалены.
Встраивание продуктов питания
Для создания системы рекомендаций по ингредиентам и рецептам было важно представить их в виде векторов. Это позволило бы математически рассчитать их контекстное сходство.
Модель Word2Vec была обучена с использованием наборов данных Recipe1M+ и K&N. В случае наборов данных Recipe1M+ и K&N ингредиенты, присутствующие в каждом рецепте, были извлечены, как описано в наборе данных Recipe1M+ и наборе данных K&N соответственно. Инструмент Word2Vec находится в свободном доступе в библиотеке Python 9.0005 Генсим .
Одним из ключевых моментов обучения модели Word2Vec является захват окружения слова. Принимая это во внимание, было принципиально важно, чтобы порядок ингредиентов в каждом рецепте соответствовал определенному критерию. В противном случае модель будет интерпретировать одни и те же ингредиенты, отсортированные по-разному, как имеющие разный контекст. По этой причине ингредиенты были отсортированы в алфавитном порядке. Корпус, введенный в качестве входных данных для модели, представлял собой набор наборов ингредиентов, присутствующих в рецептах из двух наборов данных.
Гиперпараметры, требующие соответствующей настройки: size , worker , window , sg и min_count . Размер относится к количеству измерений (100), учитываемых для каждого вектора, представляющего ингредиенты. Выбор этого значения был основан на качестве полученных вложений ингредиентов (рекомендация по ингредиентам) и точности модели, извлекающей кухни из наборов ингредиентов, представленных в разделе «Рецепт для кухни». Число рабочих было установлено равным количеству ядер (8), на которых обучалась модель — MacBook Pro 15’ Late 2016. Это значительно ускорило процесс обучения. Окно относится к максимальному расстоянию от закодированного слова, которое нужно рассматривать как неподвижную часть окружения. Для расчета этого значения были определены рецепты с наибольшим количеством ингредиентов в Recipe1M+ и K&N. Окно было установлено на 65 после нахождения рецепта с 66 элементами в наборе данных K&N. Наконец, поскольку целью модели было предсказание целевого вектора из соседних слов, был выбран Непрерывный пакет слов. Это значит, sg был введен как 1. Последним рассмотренным параметром был min_count . Чтобы получить векторное представление для каждого ингредиента, даже если он менее представлен, min_count был установлен на 1.
После получения векторов ингредиентов они были визуализированы в 2D-графиках. Это стало возможным после уменьшения их размерности с помощью инструмента, представленного в следующем разделе.
Уменьшение размерности
Чтобы уменьшить размерность вложений ингредиентов, созданных с помощью Word2Vec, со 100 до 2, был использован PCA. В scikit-learn , в пакете decomposition доступно несколько модулей для уменьшения векторных размерностей. Один из них — PCA , который использовался для визуализации всех ингредиентов в наборе данных Recipe1M+.
Кластеризация ингредиентов
Для кластеризации ингредиентов из набора данных Recipe1M+ в соответствии с их сходством к вложениям ингредиентов, созданным с помощью Word2Vec, была применена спектральная кластеризация, а размерность уменьшена с помощью PCA. Опять же, он был использован scikit-learn , но другой пакет. Кластер включает в себя множество функций, способных находить сообщества в данных, но была использована функция SpectralClustering .
Эта функция дает пользователю возможность ввести желаемое количество кластеров. Было выбрано то же число, что и количество категорий ингредиентов, которые были определены в [3] — 9. Это основное блюдо, закуска, напиток, суп/тушеное мясо, хлеб, салат, закуска, гарнир и десерт.
Recipe to Cuisine
Модель SVC была обучена предсказывать кухню рецептов на основе набора ингредиентов.
Для обучения модели был выбран набор данных K&N из-за его размера, содержащего список ингредиентов в каждом рецепте и соответствующую кухню. Тем не менее, было невозможно предоставить SVC набор строк для проведения обучения. Каждый рецепт был преобразован в вектор после усреднения всех компонентов векторного представления ингредиентов. Модель Word2Vec, представленная ранее, была обучена на данных из наборов данных Recipe1M+ и K&N, следовательно, векторные представления для каждого ингредиента во втором наборе данных уже были доступны.
Для обучения модели машины опорных векторов (SVM) использовался пакет SVM из scikit-learn . Это потребовало выбора функции, а также настройки нескольких параметров в соответствии с обучающим набором данных.
Из-за большого количества функций (100), рецептов и вычислительных ограничений, на которых обучалась модель (MacBook Pro 15’, конец 2016 г. ), было использовано линейное ядро для сокращения времени обучения. Использовалась функция LinearSVC .
Необходимо настроить несколько параметров функции. K&N оказался несбалансированным набором данных. Размеры некоторых классов (кухонь), присутствующих в наборе данных, иногда различаются на два порядка. По этой причине class_weight был установлен как сбалансированный. Это означает, что каждому классу был присвоен вес, обратно пропорциональный количеству их элементов. Затем, чтобы гарантировать сходимость обучения, было увеличено максимальное количество итераций ( max_iter ) со стандартного значения 1000 до 5000. Кроме того, всякий раз, когда наборы данных содержат большее количество элементов, чем каждый набор функций, рекомендуется установить алгоритм для решения двойной проблема с оптимизацией. Это было сделано путем установки для параметра dual значения False. Есть некоторые параметры (например, регуляризация), которые нельзя вывести напрямую из характеристик набора данных. По этой причине было важно использовать функцию GridSearchCV из пакета model_selection (также принадлежащего scikit-learn ), чтобы можно было выполнить исчерпывающий поиск по их диапазону и оптимизировать точность модели. Значения в диапазоне от 0,00001 до 10000, кратные 10, были протестированы для параметра регуляризации. 0,0001 оказался оптимальным, затем его использовали для обучения модели. Этот параметр учитывает важность, придаваемую неправильной классификации точек данных.
Классификация кухонь
Одной из целей этого проекта было ранжирование кухонь в соответствии с количеством молекул, побеждающих рак. Во-первых, было определено количество побеждающих рак молекул в каждом рецепте из набора данных Recipe1M+ с использованием полного набора ингредиентов в таблице 1 (включая непредставленные) [4]. Чтобы их названия соответствовали ингредиентам в наборе данных, они были упрощены. Например, Виноград обыкновенный был преобразован в виноград 9. 0006 . После извлечения кухонь для каждого рецепта в наборе данных с использованием SVC, представленного в Recipe to Cuisine, было рассчитано среднее присутствие молекул, борющихся с раком, в рецепте для каждой кухни.
Таблица 1 Каждый ингредиент представлен своими (модифицированными) общими и научными названиями в первой и второй колонках соответственно. Количество побеждающих рак молекул и их названия присутствуют в последних двух. Были представлены только пять ингредиентов с наибольшим количеством борющихся с раком молекул. Адаптировано из [4].
Кухни также можно классифицировать в соответствии с ожидаемым количеством негативных взаимодействий их рецептов с наркотиками. В случае с противоопухолевыми и иммуномодулирующими агентами была импортирована промилле ожидаемых вредных взаимодействий (таблица 2) [3]. Эта информация будет использоваться при прогнозировании вероятности отрицательного рецепта — взаимодействия с лекарствами после извлечения кухни из изображения рецепта с помощью приложения HyperFoods.
Таблица 2 Количество негативных взаимодействий, ожидаемых между противоопухолевыми препаратами и кухнями по всему миру [3]. Сокращения: NA (Северная Америка), WE (Западная Европа), NE (Северная Европа), EE (Восточная Европа), SE (Южная Европа), ME (Ближний Восток), SA (Южная Азия), SEA (Юго-Восточная Азия), EA (Восточная Азия), LA (Латинская Америка) и A (Африка).
Инструменты визуализации
Matplotlib, Plotly и Seaborn были тремя платформами визуализации Python, выбранными для визуализации некоторых данных проекта.
Matplotlib использовался для построения векторных вложений всех двухмерных ингредиентов в отчете. В Jupyter Notebook, доступном в репозитории проекта, можно использовать Plotly для динамической визуализации одних и тех же данных. Облегчение проверки ингредиентов за ингредиентами, поскольку их метки изначально были скрыты и появлялись только при наведении курсора мыши на соответствующие узлы. Также можно увеличивать и уменьшать масштаб, чтобы получить больше или меньше деталей соответственно.
Сиборн построил матрицу путаницы, полученную в результате оценки алгоритма поиска кухни, подробно описанного в «Рецепте кухни».
Приложение HyperFoods
В качестве шага вперед в создании новой платформы рекомендаций по ингредиентам и рецептам было разработано веб-приложение. Это позволяет предсказать ингредиенты по изображению (предоставленному URL-адресом). Предложить альтернативные ингредиенты на основе их близости в векторном пространстве вложения к ингредиентам, идентифицированным алгоритмом обратного приготовления. Предсказать кухню по полученному набору ингредиентов. И оценить вероятность отрицательного рецепта — взаимодействия противоопухолевых препаратов на основе предсказанной кухни.
Реализация бэкенда и внешнего интерфейса веб-приложения описана ниже.
Серверная часть разработана с использованием Node.js. На стороне сервера был импортирован файл, содержащий 3 наиболее похожих ингредиента из всех в словаре. Этот файл был получен после вычисления евклидова расстояния между всеми векторами в пространстве встраивания и экспорта полученного словаря в виде файла JSON. Было установлено соединение между HTML-страницей внешнего интерфейса и сервером, путем установки порта прослушивания. Оболочка Python использовалась для: выполнения алгоритма Inverse Cooking, реализованного на Python; загрузить модель Word2Vec; конвертировать ингредиенты изображений в векторы; рассчитать векторное представление для каждого рецепта и загрузить модель SVC, чтобы иметь возможность прогнозировать кухню на основе вектора рецепта. На стороне сервера реализована и выполняется функция преобразования двоичного кода обратно в строку. Из-за формата общего URL-адреса было невозможно получить ссылку из внешнего интерфейса на сервер. Итак, это было преобразовано в двоичный файл во внешнем интерфейсе и обратно в строку в бэкэнде.
Во внешнем интерфейсе использовался HTML для построения основной структуры интерфейса. CSS был использован, чтобы сделать интерфейс простым и интуитивно понятным. И, JavaScript, включил адаптивную веб-страницу и связь с сервером. Одной из фундаментальных библиотек JavaScript, которая использовалась для того, чтобы сделать веб-сайт удобным для пользователя, была уменьшенная версия D3. js версии 4. Она обрабатывала все события мыши.
После реализации бэкенда и внешнего интерфейса мы поставили перед собой цель сделать веб-приложение доступным в Интернете. Из-за ограничений размера приложения Heroku (хостинговая платформа) и размера некоторых файлов PyTorch это не было достигнуто. При выполнении алгоритма Inverse Cooking использовалась версия модуля PyTorch с поддержкой GPU и CPU. Модуль занимал в памяти более 1GB. Из-за ограничений хранилища (500 МБ) хостинговой платформы использовалась более легкая версия PyTorch, работающая только на ЦП. Это не повлияет на выполнение приложения, поскольку Heroku не обеспечивает графическую вычислительную мощность. Эта модификация уменьшила размер приложения вдвое. Но была еще обученная модель PyTorch из алгоритма Inverse Cooking, из-за которой приложение превышало ограничения памяти сервера. Одним из способов преодоления этого может быть переобучение модели с использованием меньшего набора обучающих данных, но это значительно снизит точность обнаружения. Из-за нехватки времени этот путь не был пройден. Размера модели (436 МБ) было недостаточно, чтобы превысить пороговое значение, но параллельно с пакетами Node.js и Python, которые требовались для выполнения приложения, сделать ее доступной в сети было невозможно. Тем не менее, веб-приложение все еще может работать локально после его загрузки из репозитория GitHub.
В разделе «Методология» цели проекта были подробно описаны вместе с инструментами, используемыми для их достижения. В разделе «Результаты» представлены результаты анализа и визуализации данных. Наряду с обсуждением предсказуемости результатов и их влияния.
Во-первых, представлен подробный обзор наборов данных, которые использовались для анализа данных (набор данных Recipe1M+) и обучения модели (набор данных K&N). Затем указываются вложения ингредиентов и критерии их визуализации в двумерном пространстве (рекомендация по ингредиентам). Затем производительность SVC оценивается с использованием матрицы путаницы и затем тестируется (Recipe to Cuisine). Кухни с большим количеством молекул, борющихся с раком, в рецепте ранжируются (Классификация кухонь). Наконец, представлено разработанное веб-приложение с рекомендациями по еде (HyperFoods App).
Набор данных Recipe1M+
Этот набор данных содержит 1029715 рецептов, которые состоят из 1480 различных ингредиентов.
Чтобы лучше понять источник рецептов, набор данных был проанализирован, и возвращен список просканированных веб-сайтов (таблица 3). Большинство баз данных европейские или американские. Таким образом, ожидалось, что алгоритм поиска кухни будет классифицировать большое количество рецептов по этим категориям.
Таблица 3 Удаленные веб-сайты, использованные для создания набора данных Recipe1M+, слева. В середине соответствующие URL-адреса. Справа количество рецептов из каждого источника.
Чтобы получить ингредиенты из Recipe1M+, была разработана оптимизированная версия словаря, созданная той же командой, которая выпустила набор данных.
В таблице 4 показаны 5 основных ингредиентов, которые чаще всего извлекаются из рецептов в наборе данных Recipe1M+, и соответствующее количество вхождений. Эти данные использовались при построении графика ингредиентов в двумерном векторном пространстве встраивания, и обсуждалась их актуальность с точки зрения рекомендаций по ингредиентам (рекомендация по ингредиентам).
Таблица 4 Топ-5 ингредиентов, наиболее часто встречающихся в рецептах из набора данных Recipe1M+ слева. Справа — соответствующее количество вхождений.
Набор данных Kaggle and Nature
Набор данных K&N содержит 96250 рецептов и 3904 различных ингредиента для 11 кухонь: североамериканской, западноевропейской, североевропейской, восточноевропейской, южноевропейской, ближневосточной, южноазиатской, юго-восточной Азии, восточноазиатской, латиноамериканской и Африканский. Хотя этот набор данных содержит примерно 10% от количества рецептов в Recipe1M+, он содержит более чем вдвое больше различных ингредиентов. Это происходит потому, что простые ингредиенты, такие как сахар, в этом наборе данных разделены на разные ингредиенты в зависимости от их цвета или происхождения (например, органический сахар-песок, сверхтонкий белый сахар, сахар для выпечки…).
В Таблице 5 представлены 5 самых распространенных ингредиентов. Наиболее распространенные ингредиенты в наборах данных Recipe1M+ и K&N значительно перекрываются. В топ-5 лук и перец присутствуют в обоих наборах данных.
Таблица 5 Слева ингредиенты, наиболее часто встречающиеся в наборе данных K&N. Справа соответствующее количество присутствий.
В таблице 6 представлено распределение кухонь в наборе данных по количеству рецептов. В наборе данных K&N обнаружен дисбаланс по количеству рецептов для каждой кухни. Североамериканская кухня содержит на 2 порядка больше рецептов, чем восточноевропейская. Это повлияет на точность модели SVC (матрица путаницы) при прогнозировании кухни по списку ингредиентов.
Таблица 6 Количество рецептов различных кухонь в наборе данных K&N. Сокращения: NA (Северная Америка), WE (Западная Европа), NE (Северная Европа), EE (Восточная Европа), SE (Южная Европа), ME (Ближний Восток), SA (Южная Азия), SEA (Юго-Восточная Азия), EA (Восточная Азия), LA (Латинская Америка) и A (Африка)
Рекомендация по ингредиентам
После представления каждого ингредиента, присутствующего в наборе данных Recipe1M+, в виде 100 признаков, встраивания и уменьшения размерности до двумерного пространства был получен график на рисунке 4. Для ясности все ингредиенты, встречающиеся в наборе данных менее 4500 раз, не представлены. Разные цвета соответствуют разным кластерам, которые были идентифицированы с помощью спектральной кластеризации.
Выявлена спектральная кластеризация Салаты , Азиатские блюда , Фрукты и орехи и Десерты категории (рис. 4).
Рисунок 4 Сходство контекста для нескольких ингредиентов в Recipe1M+. Представлены только те, у которых в наборе данных не менее 4500 вхождений. Ингредиенты окрашены в соответствии с кластером, к которому они принадлежат.
Это представление пищи позволяет нам извлечь информацию о том, какие ингредиенты чаще всего встречаются вместе. Следовательно, он предлагает основу для опробования новых комбинаций на основе их близости в сюжете. Чем больше радиус перекрывающихся ингредиентов, тем больше уверенность в успехе их сочетания.
Некоторые удачные комбинации: чеснок, курица и лук; помидор, базилик и сельдерей или мед и апельсин.
То же изображение было перепечатано, но с другим критерием окраски. На этот раз ингредиенты, содержащие хотя бы одну молекулу, побеждающую рак, были окрашены в зеленый цвет, а остальные — в черный (рис. 5).
Рисунок 5 Контекстное сходство ингредиентов в Recipe1M+. Представлены только те, у которых в наборе данных не менее 4500 вхождений. Зеленые узлы (ингредиенты) содержат как минимум 1 молекулу, побеждающую рак.
Идентифицируя ингредиенты, которые ближе всего к ингредиентам, содержащим молекулы, побеждающие рак (зеленые точки), можно предположить, что, учитывая схожий контекст, в котором они присутствуют в рецептах, вероятность найти те же самые молекулы в рецептах выше, чем в рецептах. любые другие.
Более того, рисунок 5 дает нам информацию не только об ингредиентах, которые обычно встречаются одновременно, но также предоставляет пользователю информацию об их содержании в молекулах, побеждающих рак. Таким образом, пользователь может учитывать их противораковые свойства, учитывая сходство контекста. Некоторые возможные комбинации были найдены и представлены на рисунке 6.9.0003 Рисунок 6 Корица, грецкий орех и клюква; арахис и манго являются двумя наиболее успешными комбинациями ингредиентов после наблюдения за рис. 5. наборы данных рецептов Recipe1M+ и K&N. В этом разделе его точность оценивается после построения матрицы путаницы, модель тестируется в наборе данных Recipe1M+, и определяются некоторые ингредиенты, играющие важную роль в классификации кухни.
Матрица путаницы
Чтобы понять, как классификатор обнаруживает разные кухни, из обучающего набора была рассчитана многомерная матрица путаницы (рис. 7). Он включает прогноз для каждой из 11 кухонь в наборе данных рецептов K&N.
Рис. 7 Матрица путаницы для модели SVM, обученной с использованием набора данных K&N. Каждая строка вместе с соответствующими значениями представляет пропорцию ингредиентов, правильно отнесенных к реальной кухне. Каждый столбец — это кухня, предсказанная алгоритмом.
Рецепты, относящиеся к регионам Северной Европы, Восточной Европы, Западной Европы и Ближнего Востока, часто ошибочно классифицировались как североамериканские. В случае Северной Европы, Восточной Европы и Ближнего Востока это может быть связано с их недостаточной представленностью в наборе данных: 739 381 и 645 рецептов соответственно. А также преобладание североамериканской кухни.
Другим важным фактором являются общие ингредиенты. На самом деле, все европейские кухни часто ошибочно причисляются к ним. Например, 11,5% североевропейских рецептов были ошибочно классифицированы как западноевропейские. Европа – континент, представленный наибольшим количеством кухонь (4). Это может снижать специфичность среди них.
Модель была более точной при прогнозировании восточноазиатских, южноазиатских и североамериканских рецептов. На самом деле, это было правильно в 84,8%, 83,4% и 73,0% из них соответственно.
Тестирование классификатора
После обучения классификатора он использовался для прогнозирования кухни каждого рецепта в наборе данных Recipe1M+. Соответствующие пропорции представлены в таблице 7.
Для проверки классификатора был использован следующий подход: сначала все рецепты со словом чай , присутствующий в заголовке, был извлечен. Затем было рассчитано окончательное распределение кухни (Таблица 7).
Таблица 7 Распределение кухонь в Recipe1M+. Плюс фильтрация тех, которые содержат ключевые слова салат и чай в заголовке.
Как и ожидалось, большинство рецептов, содержащих в названии слово чай, были отнесены, во-первых, к восточноазиатской (27% рецептов) и, во-вторых, к североевропейской (25% рецептов) кухням (рис.
Эти две области гораздо больше представлены в избранных рецептах чая, чем в общем наборе данных Recipe1M+. В Восточной Азии Китай является крупнейшим абсолютным потребителем чая в мире — 1,6 миллиарда фунтов стерлингов в год [23]. Из стран Северной Европы Ирландия, Великобритания и Россия входят в четверку стран с более высоким уровнем потребления на душу населения [23]. С другой стороны, южноевропейская страна с самым высоким рейтингом в списке (Испания) занимает только 40-е место по потреблению чая на душу населения [23]. И действительно, самое большое падение набора данных (с 21% до 5%) зафиксировано именно для этого региона.
Рисунок 8 Нормы потребления чая в мире на человека в год. [23]
Классификация кухонь
Для того чтобы проанализировать наличие молекул, побеждающих рак, среди различных кухонь, была использована информация о количестве молекул, побеждающих рак, в каждом рецепте. После усреднения этого числа по всем рецептам в категории кухни был определен балл для каждого из них (таблица 8).
Таблица 8 Среднее количество побеждающих рак молекул на рецепт для каждой из 11 представленных кухонь. Сокращения: NA (Северная Америка), WE (Западная Европа), NE (Северная Европа), EE (Восточная Европа), SE (Южная Европа), ME (Ближний Восток), SA (Южная Азия), SEA (Юго-Восточная Азия), EA (Восточная Азия), LA (Латинская Америка) и A (Африка).
Наивысшие противораковые показатели были получены в трех регионах Средиземноморья: Южная Европа, Ближний Восток и Африка (рис. 9). С другой стороны, североамериканская кухня отличается наименьшим количеством молекул, побеждающих рак.
Эти результаты согласуются с прогнозами для североамериканской кухни, которую часто классифицируют как нездоровую и положительно коррелируют с заболеваемостью онкологическими заболеваниями [24]. И средиземноморская диета, богатая фруктами и овощами, которую часто называют профилактической от рака [25].
Рисунок 9 Кухни, содержащие рецепты с большим количеством борющихся с раком молекул. Карта мира, созданная с использованием [26].
Для того, чтобы понять, какие ингредиенты могут быть ответственны за высокий рейтинг южно-европейской, ближневосточной и африканской кухонь, было рассчитано их распределение, принимая во внимание только те, которые содержат ключевое слово салат в своем названии (таблица 7).
Таблица 7 показывает, что рецепты салатов в основном относились к южноевропейской кухне. Они могут быть одной из главных причин увеличения противоракового балла этой кухни, поскольку большинство ингредиентов, представленных в полной версии Таблицы 1, обычно встречаются в салатах. Кроме того, следует отметить, что одним из основных компонентов южноевропейской диеты является салат [27].
Приложение HyperFoods
В верхней части веб-страницы FoodReco получает URL-адрес изображения, доступного в Интернете, и возвращает список предсказанных ингредиентов после выполнения алгоритма обратного приготовления. Они будут отображаться под изображением, которое было обработано. При наведении курсора мыши на каждый ингредиент отображается упорядоченный список из трех основных ингредиентов, которые чаще всего встречаются в Recipe1M+ и K&N. Внизу отображается предсказанная кухня, основанная на наборе ингредиентов. Цвет фона этого текстового поля зеленый, если количество негативных взаимодействий с лекарствами ниже среднего, или красный, если выше для противоопухолевых препаратов (рис. 10). Это значение рассчитывается после усреднения всех промиллежей из таблицы 2.
Веб-приложение доступно для загрузки здесь.
Рисунок 10 Интерфейс веб-приложения FoodReco. Он может предсказать ингредиенты по изображению, предложить 3 замены ингредиентов для каждого и найти наиболее вероятную кухню, к которой принадлежит блюдо.
Цель этого проекта заключалась в том, чтобы использовать крупнейшую общедоступную коллекцию данных рецептов (Recipe1M+) для создания системы рекомендаций по ингредиентам и рецептам. Обучайте, оценивайте и тестируйте модель, способную предсказывать кухни по наборам ингредиентов. Предсказать вероятность отрицательного взаимодействия рецепт-лекарство на основе предсказанной кухни. Наконец, создание веб-приложения в качестве шага вперед в создании системы рекомендаций, которая учитывает вкусовые предпочтения пользователя, максимизирует количество полезных соединений и минимизирует вредные для здоровья в пище.
С помощью Word2Vec было создано векторное представление для каждого ингредиента. Путем усреднения всех компонентов векторизованных ингредиентов было получено аналогичное представление для рецептов. Модель SVC была обучена возвращать кухни рецептов из их набора ингредиентов. Кухня Южной Азии, Восточной Азии и Северной Америки была предсказана с точностью более 73%. Африканская, южноевропейская и ближневосточная кухни содержат наибольшее количество молекул, борющихся с раком. Наконец, было разработано веб-приложение, способное предсказывать ингредиенты по изображению, предлагать новые комбинации и извлекать кухню, к которой принадлежит рецепт, а также оценивать ожидаемое количество негативных взаимодействий с противоопухолевыми препаратами. Сделать его доступным онлайн не удалось, но его можно выполнить локально (github.com/warcraft12321/HyperFoods).
Будущие усовершенствования подхода, используемого в этом проекте, заключаются в создании более полного и точного словаря ингредиентов. Перед внедрением ингредиентов с помощью Word2Vec унификация ингредиентов, представленных в наборах данных Recipe1M+ и K&N, может повысить точность встраивания и SVC. Создание векторов для рецептов с учетом соотношения различных ингредиентов. Один шаг в этом направлении был сделан в этом проекте путем разработки словаря, включающего все единицы (обычные и из обычных метрических систем), присутствующие в наборе данных Recipe1M+. А также система преобразования всех идентифицированных единиц в граммы. Для обучения модели SVC поиска кухни можно было использовать другие ядра, кроме линейного. Или глубокое обучение, используемое для оптимизации той же проблемы. Наконец, хотя веб-приложение без проблем работает на локальном компьютере, следующим шагом будет сделать его доступным в Интернете и с расширенным набором функций, таких как: добавление дополнительных рекомендаций по питанию для выбора ингредиентов, богатых молекулами, которые побеждают рак (HyperFoods), уменьшая при этом количество негативных взаимодействий между наркотиками и кухней для других типов лекарств, кроме противоопухолевых.
Отчет | Плакат | Репозиторий GitHub
[1] Х. Арем и Э. Лофтфилд, «Эпидемиология рака: обзор изменяемых факторов риска для профилактики и выживания», Американский журнал медицины образа жизни, том. 12, нет. 3, с. 200–210, 2018.
[2] М. С. Дональдсон, «Питание и рак», Nutrition Journal, vol. 3, pp. 19–25, 2004.
[3] М. Йовановик, А. Богоеска и Д.Э. а. Траджанов, «Определение взаимодействий между кухней и лекарствами с использованием подхода связанных данных», Научные отчеты, том. 5, нет. 9346, 2015.
[4] Веселков К., Гонсалес Г., Альджифри С., Галеа Д., Мирнезами Р., Юссеф Дж., Бронштейн М., Лапоногов И. «Гиперфуды: машинное интеллектуальное картирование раковых заболеваний». избиение молекул в продуктах питания», Scientific Reports, vol. 3, нет. 9237, 2019.
[5] К. Андерсон, «Опрос лиц, рекомендующих продукты питания», ArXiv, vol. abs/1809.02862, 2018.
[6] Дж. Р. Аунан, В. К. Чо и К. Сёрейде, «Биология старения и рака: краткий обзор общих и расходящихся молекулярных признаков», Старение и болезни, vol. 8, нет. 5, с. 628–642, 2017.
[7] «IHME, Global Burden of Disease, Our World in Data», 2016. [Онлайн]. Доступно: http://www.healthdata.org/gbd. [По состоянию на 8 марта 2020 г.].
[8] М. Чари, С. Парих, А. Ф. Манини, Э. В. Бойер и М. Радеос, «Обзор обработки естественного языка в медицинском образовании», The Western Journal of Emergency Medicine, vol. 20, нет. 1, 2019.
[9] Т. Миколов, К. Чен, Г. Коррадо и Дж. Дин, «Эффективная оценка представлений слов в векторном пространстве», Proceedings of the International Conference on Learning Representations, 2013.
[10] R. Řehůřek, «gensim: тематическое моделирование для людей», [онлайн]. Доступно: https://radimrehurek.com/gensim/. [По состоянию на 8 марта 2020 г.].
[11] А. Сальвадор, М. Дроздзал, X. Джиро-и-Нието и А. Ромеро, «Обратное приготовление пищи: создание рецептов из изображений продуктов», Компьютерное зрение и распознавание образов, 2018.
[12 ] А. Сальвадор, Н. Хайнс, Ю. Айтар, Дж. Марин, Ф. Офли, И. Вебер и А. Торральба, «Изучение кросс-модальных вложений для рецептов приготовления и изображений еды», Computer Vision and Pattern Recognition, 2017.
[13] И. Т. Джоллифф и Дж. Кадима, «Анализ основных компонентов: обзор и последние разработки», Philosophical Transactions of The Royal Society A Mathematical Physical and Engineering Sciences, vol. . 374, нет. 2065, 2016.
[14] Л. в. д. Маатен и Г. Хинтон, «Визуализация данных с использованием t-SNE», Journal of Machine Learning Research, vol. 9, pp. 2579–2605, 2008.
[15] В.Д. Блондель, Ж.-Л. Гийом, Р. Ламбиотт и Э. Лефевр, «Быстрое развертывание сообществ в больших сетях», J. Стат. Mech., , 2008.
[16] М. Росвалл, Д. Аксельссон и К. Т. Бергстром, «Уравнение карты», , Европейский физический журнал, специальные темы, , том. 178, нет. 1, pp. 13–23, 2009.
[17] А. Ю. Нг, М. И. Джордан, Ю. Вайс, «О спектральной кластеризации: анализ и алгоритм», Труды 14-й Международной конференции по нейронным системам обработки информации: естественные и Синтетика, р. 849–856, 2001.
[18] «Matplotlib: построение графиков на Python», Matplotlib, [онлайн]. Доступно: https://matplotlib.org/. [По состоянию на 8 марта 2020 г.].
[19] «Plotly: современные аналитические приложения для предприятия», Plotly, [онлайн]. Доступно: https://plot.ly/. [По состоянию на 8 марта 2020 г.].
[20] «Seaborn: визуализация статистических данных», Seaborn, [онлайн]. Доступно: https://seaborn.pydata.org/. [По состоянию на 8 марта 2020 г.].
[21] «панды», [онлайн]. Доступно: https://pandas.pydata.org/. [По состоянию на 8 марта 2020 г.].
[22] Дж. Марин, А. Бисвас, Ф. Оффли, Н. Хайнс, А. Сальвадор, Ю. Айтар, И. Вебер и А. Торральба, «Recipe1M+: набор данных для изучения кросс-модальных вложений для приготовления пищи». Рецепты и изображения еды», IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019.
[23] Р. А. Фердман, «Карта: страны, которые пьют больше всего чая», The Atlantic, 21 января 2014 г. [онлайн]. Доступно: https://www.theatlantic.com/international/archive/2014/01/map-the-countries-that-drink-the-most-tea/283231/. [По состоянию на 7 марта 2020 г.].
[24] М. С. Дональдсон, «Питание и рак: обзор доказательств противораковой диеты», Nutrition Journal, vol. 3, нет. 19, 2004.
[25] А. Марука, Р. Каталано, Д. Багетта, Ф. Месити, Ф. А. Амбросио, И. Ромео, Ф. Морака, Р. Рокка, Ф. Ортузо, А. Артезе, Г. Коста , S. Alcaro и A. Lupia, «Средиземноморская диета как источник биоактивных соединений с многоцелевым противораковым профилем», European Journal of Medicinal Chemistry, vol. 181, 2019.
[26] «Карта», [онлайн]. Доступно: https://mapchart.net/world.html. [По состоянию на 7 марта 2020 г.].
[27] К. М. Лэкэтушу, Э. Д. Григореску, М. Флория, А. Онофриску и Б. М. Михай, «Средиземноморская диета: от культуры питания, ориентированной на окружающую среду, к новым медицинским рецептам», Международный журнал экологических исследований и общественного здравоохранения, vol. 6, нет. 16, 2019.
[28] «Project Jupyter», Jupyter, [онлайн]. Доступно: https://jupyter.org/. [По состоянию на 8 марта 2020 г.].
Прогноз времени доставки еды: как это работает?
Прогнозирование времени доставки давно стало частью городской логистики, но в последнее время точность уточнения стала очень важной для таких сервисов, как Deliveroo, Foodpanda и Uber Eats, которые доставляют еду по требованию.
Эти службы должны получить заказ и доставить его в течение 30 минут, чтобы успокоить своих пользователей. В этих ситуациях +/- пять минут могут иметь большое значение, поэтому для удовлетворения клиентов важно, чтобы первоначальный прогноз был точным и чтобы о любых задержках сообщалось эффективно.
В этой статье я расскажу о своем опыте создания реальной модели прогнозирования времени доставки для стартапа по доставке еды и о том, как она давала более точные прогнозы, чем наша обученная операционная команда. Я коснусь технических тем машинного обучения, сосредоточившись на бизнес-знаниях, необходимых для создания хорошо функционирующей прогностической модели.
Прогнозирование сроков пищи. . Это поможет нам оставаться сосредоточенными на цели.
Мы хотели бы построить модель, которая будет принимать данные о доставке еды в качестве входных данных, а затем выводить желаемое время получения, которое будет сообщено водителям.
На что еще обратить внимание:
- Поставки большие. Можно предположить, что им нужны автомобили.
- Поставщик (или поставщики) варьируется от ресторанов до предприятий общественного питания и может иметь самые разные характеристики.
- Предположим, водители прибывают к поставщику точно в назначенное время. На самом деле это не всегда так, но при достаточном количестве драйверов аберрации можно свести к минимуму.
- Еда не должна доставляться слишком поздно, так как клиент будет ждать и злиться; и при этом он не может прийти слишком рано, так как ему придется отсидеть до того, как покупатель будет готов его съесть.
Еще от JyeRage против машинного обучения: моя война с механизмами рекомендаций
Пример данных, доступных для доставки:
Команда доставки: Delivery's 'R' Us ID_заказа: 12345 Agent_Name : Боб Драйвер Поставщик : Вкусные пончики Заказчик: Big Corporation Inc.
Поскольку у нас много текста, нам нужно сначала обработать данные, чтобы получить их в машиночитаемом формате.
Адреса можно обрабатывать с помощью регулярных выражений для получения более структурированной информации. Ключевыми моментами являются: этаж, здание, почтовый индекс, район и страна.
После описанной выше обработки здание, районы и почтовые индексы могут быть объединены с другими переменными для выполнения прямого кодирования. Горячее кодирование создаст множество двоичных переменных для каждого возможного текста. Затем мы можем передать эти числовые переменные в наши модели.
Обучение
Для обучения модели мы будем использовать данные предыдущих доставок, включая прогнозируемое время доставки и фактическое время доставки (целевая переменная для нашего упражнения). Для целей этой статьи мы будем работать примерно с 1000 точками данных.
Подробнее о доставке и машинном обучении TechDelivering with Data: как системы данных повышают эффективность вашей деятельности . Диаграмма ниже из документации scikit-learn дает отличный способ решить, какой алгоритм вам следует использовать.
Кто сказал, что машинное обучение — сложная дисциплина? Кредит: документация Scikit-Learn.
Давайте посмотрим, что мы знаем о нашей проблеме:
- Как упоминалось ранее, у нас есть более 1000 точек данных для обучения.
- Выход модели должен быть числовым значением.
- Из-за одноразового кодирования у нас остается довольно большое количество двоичных переменных, что означает, что многие функции, вероятно, важны.
Имея это в виду, мы можем следовать приведенной выше диаграмме, чтобы получить гребневую регрессию и SVR с линейным ядром. Для простоты мы просто будем работать с гребневой регрессией, а также добавим регрессор случайного леса, чтобы увидеть, как он по-разному работает с данными.
Если вас интересуют дополнительные сведения, вы можете прочитать об алгоритмах на соответствующих страницах в документации scikit-learn: гребневая регрессия, SVR (регрессия опорных векторов) и регрессия случайного леса.
Показатели производительности
Также следует обратить внимание на показатель, который мы будем использовать для оценки эффективности нашей модели.
Распространенным показателем, позволяющим быстро получить представление о нашей производительности, является средняя абсолютная ошибка (MAE). Это говорит нам о средней разнице между нашими оценками времени доставки и фактическим временем доставки.
Затем мы можем определить еще две метрики, специфичные для домена:
- Практически вовремя (опоздание < пяти минут)
- Хорошо, мы немного опоздали (опоздание < 10 минут)
Эти две метрики расскажите нам, как часто мы будем расстраивать пользователей. Если мы опаздываем на 15 минут или на 25 минут, для пользователя это не имеет особого значения, мы просто действительно опаздываем . MAE этого не осознает и посчитает одно хуже другого, но с точки зрения бизнеса это фактически одно и то же, и важно, чтобы наша модель понимала это.
Примечание. На самом деле мы будем использовать обратную величину этих показателей (т. е. доставку с опозданием более чем на пять минут), так как с ними немного проще работать.
Итак, краткий обзор: мы знаем, что нам нужно сделать, мы знаем, с какими данными мы должны это сделать, и мы знаем, как мы собираемся это сделать — так что давайте действовать!
Еще от экспертов по встроенному машинному обучению. 7 наиболее распространенных функций потери машинного обучения. Мы можем разбить его на три основных компонента:
- Забрать еду у поставщика.
- Проезд от поставщика к заказчику.
- Отдайте еду покупателю.
Мы можем предсказать время, необходимое для каждого компонента, а затем сложить их вместе, чтобы получить окончательное время доставки.
Время доставки = время получения + время доставки + время доставки Причина, по которой мы должны разбить это, состоит в том, чтобы создать специальные модели , которые будут иметь превосходящие возможности по сравнению с одной общей моделью. Если мы думаем о моделях как о людях, это имеет смысл. В вашей команде по развитию бизнеса у вас должен быть человек, который действительно хорошо знает поставщиков и то, сколько времени им может потребоваться для доставки. В вашей команде обслуживания клиентов должен быть кто-то, кто хорошо знает каждого клиента и может предсказать, сколько времени может занять доставка, исходя из их местоположения и здания. Мы структурируем наш процесс с учетом этого.
Теперь, когда у нас есть три этапа, давайте погрузимся в них и построим наши модели.
Доставка поставщиком
Когда водитель прибывает в пункт назначения, он должен найти место для парковки, забрать еду и вернуться к машине. Давайте рассмотрим возможные осложнения, которые могут возникнуть во время этого процесса.
- Нет парковки: Для ресторанов, расположенных в центре города, это может быть значительно сложнее, чем для ресторанов, расположенных в более жилых районах. Чтобы получить эту информацию, мы можем использовать почтовый индекс или информацию о широте/долготе. Я обнаружил, что почтовые индексы были особенно ценны, поскольку они собирали общую информацию высокого уровня из-за своей специфической структуры.
- Трудный доступ: Рестораны, как правило, довольно легкодоступны, поскольку они полагаются на это для обслуживания клиентов, но поставщики общественного питания могут находиться в промышленных зонах без явного входа, что затрудняет работу водителей. Мы также можем использовать информацию о местоположении при добавлении категории поставщика.
- Еда не готова: Поскольку размеры заказа могут быть довольно большими, еда нередко оказывается неподготовленной. Чтобы справиться с этим, можно связаться с провизором в день доставки, чтобы убедиться, что еда будет готова вовремя. Ответ на эти сообщения был бы полезным способом понять наше время. Полезным входом также может быть наличие истории у конкретного поставщика. Наконец, размер ордера — хороший показатель; мало что может пойти не так при приготовлении небольшого количества еды, но когда вы кормите 100 человек, вероятность того, что что-то пойдет не так, гораздо выше.
- Что-то отсутствует в заказе: Водитель должен проверить заказ по прибытии, и в некоторых случаях он может обнаружить, что чего-то не хватает. Это означает, что они должны ждать, пока будет приготовлена дополнительная еда. Опять же, это, вероятно, зависит от поставщика и от того, насколько он занят во время получения.
Для этой части задачи мы будем использовать следующие точки данных:
Поставщик: Delicious Donuts Заказчик: Big Corporation Inc. Pickup_Address : Shop 1, Busy Street, 23456, Гонконг Время доставки : 29/05/2016 08:00:00 Order_Size : $500
После выполнения обработки, как описано выше, мы можем передать данные в наши модели scikit-learn, в результате чего получится следующее:
Базовые результаты: Средняя абсолютная ошибка: 544 секунды Опоздание более чем на 5 минут: 55% Опоздание более чем на 10 минут: 19% Результаты случайного леса: Средняя абсолютная ошибка: 575 секунд Опоздание более чем на 5 минут: 42% Опоздание более чем на 10 минут: 22% Результаты линейного регрессора: Средняя абсолютная ошибка: 550 секунд Опоздание более чем на 5 минут: 44% Опоздание более чем на 10 минут: 17% Результаты ансамбля: Средняя абсолютная ошибка: 549секунды Опоздание более чем на 5 минут: 45% Опоздание более чем на 10 минут: 17%
Как видите, если мы используем базовую метрику средней абсолютной ошибки (MAE), все модели работают хуже, чем базовая модель. Однако, если мы посмотрим на метрики, которые более актуальны для бизнеса по доставке еды, мы увидим, что каждая модель имеет свои преимущества.
Модель случайного леса снижает количество заказов, опоздавших более чем на пять минут, почти на 25 процентов. Линейный регрессор лучше всего справляется с сокращением заказов, опоздавших на 10 минут, примерно на 10 процентов. Интересно, что ансамблевая модель неплохо справляется с обеими метриками, но, что примечательно, она имеет наименьшую MAE из трех моделей.
При выборе правильной модели на первое место выходят бизнес-цели, определяющие выбор важных показателей и, следовательно, правильную модель. С этой мотивацией мы будем придерживаться модели ансамбля.
Точка-точка
Оценка времени в пути между пунктами назначения является сложной задачей по многим причинам; тысячи маршрутов на выбор, постоянно меняющиеся условия движения, перекрытые дороги и аварии; все это не дает ничего, кроме непредсказуемости для любой модели, которую вы создаете.
К счастью для нас, есть компания, которая долго и упорно размышляла над этой проблемой и собрала миллионы точек данных, чтобы помочь лучше понять окружающую среду. Может быть, вы слышали об этом?
Наш друг (и потенциальный будущий повелитель). Предоставлено: Wikimedia
Чтобы предсказать время в пути от точки к точке, мы вызовем API Карт Google с известными точками посадки и высадки. Возвращаемые результаты включают параметры, учитывающие трафик и сценарии наихудшего случая, которые можно использовать в качестве входных данных для модели. Вызов API достаточно прост, выглядит он так:
gmaps = googlemaps.Client(key='MY_API_KEY')
params = {'режим': 'вождение',
«альтернативы»: Ложь,
«избегать»: «пошлины»,
'язык': 'ан',
«единицы»: «метрика»,
'регион': страна}
направления_результат = gmaps.directions(pick_up_location,
drop_off_location,
прибытия_время=прибытие_время,
** параметры)
Благодаря этому мы можем получить очень точный результат для уже хорошо продуманной проблемы.
Перед внедрением этой модели наша организация использовала общедоступный интерфейс Google Maps для прогнозирования времени доставки, поэтому производительность нашей новой модели для этой части пути идентична базовой. Таким образом, мы не будем рассчитывать здесь никаких сравнений.
Важно отметить, что адреса не всегда правильно отформатированы! При запросе к Google Maps всегда есть шанс, что они ответят: « Э-э… я не знаю, », на который у нас должен быть ответ. Это отличный пример того, как люди и машины должны работать вместе. Всякий раз, когда адрес сформирован неправильно, оператор может вмешаться и уточнить адрес или даже позвонить клиенту для уточнения информации.
Теперь мы можем перейти к третьей части нашей модели.
Высадка клиентов
Как только водитель прибудет на место, он должен найти парковку, передать еду нужному человеку и получить окончательную расписку. Потенциальные проблемы на пути включают:
- Гараж имеет ограничения по высоте: Это просто, но многие доставки осуществляются в фургонах, и в этом случае могут быть ограничения по высоте, не позволяющие водителям использовать главный вход.
- У здания нет парковки: Это очевидно. Отсутствие парковки означает, что водитель должен посвятить время разъездам и поискам места, где можно оставить свой автомобиль во время доставки, или даже рисковать незаконной парковкой, чтобы осуществить доставку.
- Проблема безопасности здания: В большинстве современных офисных зданий для доступа требуется карта безопасности. В лучшем случае водителей можно просто провести, но в худшем случае от водителей могут потребовать пойти в отдельное место, подписаться на карту, а затем использовать черный ход.
- Клиент на верхнем этаже или в сложном месте : Это может показаться смешным, но в некоторых офисных зданиях очень сложно перемещаться из-за разных лифтов для разных этажей. Для небольших компаний их можно спрятать в лабиринте коридоров.
При всем этом почтовый индекс является отличным индикатором, потому что он говорит нам, можем ли мы ожидать деловой район или жилой район. Мы также можем углубиться в адрес. Например, если у нас есть 40-й этаж, совершенно очевидно, что доставка осуществляется в большом многоквартирном доме и, вероятно, будет иметь сложный процесс безопасности.
Для этой части задачи мы будем использовать следующие точки данных.
Заказчик: Big Corporation Inc. Delivery_Address : Уровень 9, небоскреб, 34567, Гонконг Время доставки : 29.05.2016 08:00:00 Размер_Заказа: 500 долл. США
После выполнения типичной обработки и запуска наших моделей мы видим следующее:
Базовые результаты: Средняя абсолютная ошибка: 351 секунда Опоздание более чем на 5 минут: 35% Опоздание более чем на 10 минут: 0% Результаты случайного леса: Средняя абсолютная ошибка: 296 секунд Опоздание более чем на 5 минут: 15% Опоздание более чем на 10 минут: 7% Результаты линейного регрессора: Средняя абсолютная ошибка: 300 секунд Опоздание более чем на 5 минут: 14% Опоздание более чем на 10 минут: 5% Результаты ансамбля: Средняя абсолютная ошибка: 293 секунды Опоздание более чем на 5 минут: 13% Опоздание более чем на 10 минут: 6%
Здесь мы видим снижение MAE на 17 процентов — намного лучше, чем раньше. Точно так же мы наблюдаем сокращение количества заказов, опоздавших более чем на пять минут, на огромные 63 процента. С другой стороны, модель увеличивает количество просроченных заказов с нуля до шести процентов. Опять же, мы сталкиваемся с компромиссом между моделями, каждая из которых имеет свои достоинства, и мы должны позволить нашим бизнес-KPI быть решающими факторами.
Собираем все вместе
Теперь мы можем объединить наши модели по следующей формуле:
Время доставки = Время получения + Время доставки + Время возврата + Гиперпараметр
На этот раз обратите внимание на добавление гиперпараметра. Мы добавим это, чтобы учесть любые другие странные эффекты, которые мы видим в данных, таких как время посадки всегда устанавливается на пять минут раньше, чтобы оправдать ожидания водителей. Мы установим этот параметр, чтобы минимизировать окончательные метрики ошибок после вычисления объединенных результатов.
Собрав все вместе, мы получаем окончательный результат:
Исходные результаты: Средняя абсолютная ошибка: 1429 секунд Опоздание более чем на 5 минут: 60% Опоздание более чем на 10 минут: 19% Результаты ансамбля: Средняя абсолютная ошибка: 1263 секунды Опоздание более чем на 5 минут: 41% Опоздание более чем на 10 минут: 12%
Таким образом, наша окончательная модель имеет значительное улучшение по сравнению с базовой моделью по всем показателям; мы сделали это!
Самое главное, мы заметили сокращение заказов с опозданием более чем на 10 минут — почти на 40 процентов! Мы смогли добиться этого, работая над тремя отдельными моделями, которые были оптимизированы для решения конкретных бизнес-задач. Объединение моделей и доводка на последнем этапе помогают гарантировать, что мы создали модель на уровне подготовленных профессионалов.
Дополнительные руководства от встроенных экспертов4 Инструменты для ускорения исследовательского анализа данных (EDA) в Python больше усилий по закону убывающей отдачи. Вместо этого есть другие решения, если мы больше думаем о бизнес-кейсе, а не о машинном обучении.
Опоздание и опоздание
Как вы помните с самого начала, эта модель предназначена для доставки еды, а это значит, что мы заранее знаем время доставки. Один из простых способов избежать поздних поставок — взять любое значение, выдаваемое моделью, и увеличить его, чтобы убедиться, что мы приходим достаточно рано.
Это не очень хорошее решение, потому что слишком раннее — это тоже проблема. Еда может испортиться или быть неподготовленной. Тем не менее, это поднимает вопрос о том, что мы должны учитывать распределение опозданий и раннее. Может быть, лучше, если мы придем на 10 минут раньше, чем если опоздаем на пять минут. С метриками, которые использовались до этого момента, мы не оптимизировали для таких сценариев, поэтому мы можем пересмотреть это и внести соответствующие коррективы.
Доставка Windows
Еще одна вещь, которую следует учитывать, — это то, как модель представлена пользователям. Если пользователю говорят, что вы приедете в 14:00. а вы нет, они будут разочарованы. Если вы скажете кому-нибудь, что будете там между 13:45 и 14:00. тогда вы можете стремиться доставить в 13:50, и если вы немного опоздаете, у вас есть свобода действий.
Всегда важно рассматривать проблемы машинного обучения как решение реальной проблемы реального мира, иначе вы можете разрабатывать так называемые улучшения, которые в противном случае были бы невозможны из самой модели.
Обратная связь с поставщиками
Одним из ключевых преимуществ этой модели было эффективное разграничение времени подготовки поставщиков. Это говорит нам о том, что у поставщиков должны быть очень разные показатели.
Углубившись в данные, мы обнаружили, что водители тратят в три раза больше минут у нескольких поставщиков. Обладая этой информацией, мы могли бы поговорить с поставщиками и выявить проблемы, чтобы в конечном итоге сократить время, которое водители проводят у этих поставщиков. Уменьшая вариацию, мы улучшаем общую производительность модели.
Мы не только разбили нашу проблему на три компонента, чтобы построить целевые модели и создать полнофункциональную прогностическую модель, но и использовали наши бизнес-знания для повышения эффективности нашей модели.
Это привело к 40-процентному сокращению количества заказов, опоздавших более чем на 10 минут. Такой прогресс напрямую выражается в долларах, сэкономленных на возмещении. Модель также помогла снизить нагрузку на операционную группу, что позволило им сосредоточиться на более важных задачах, таких как повышение эффективности работы поставщиков.
Это общая процедура, которую можно использовать для применения машинного обучения для решения бизнес-задач. Это подход, который гарантирует, что вы получите правильную основу, прежде чем оптимизировать несколько дополнительных процентов улучшения. Это методология, которую я успешно использовал, и я надеюсь, что вы тоже сможете.
Алгоритм планирования этапов приготовления с системой помощи при приготовлении домашней пищи
- title={Алгоритм планирования этапов приготовления с системой управления для домашней кулинарии},
автор={Юкико Мацусима и Нобуо Фунабики},
журнал = {IEICE Trans. Инф. сист.},
год = {2015},
объем = {98-D},
страницы={1439-1448}
}- Ю. Мацусима, Н. Фунабики
- Опубликовано 1 августа 2015 г.
- Информатика
- IEICE Trans. Инф. Сист.
Домашняя кухня играет ключевую роль в здоровой и экономичной жизни.
К сожалению, приготовление нескольких блюд обычно занимает много времени. В этой статье предлагается алгоритм минимизации времени приготовления путем планирования этапа приготовления нескольких блюд. Процедура приготовления блюда разделена на последовательность из шести типов этапов приготовления, чтобы учесть ограничения поваров и кухонной утвари на кухне. Представлена модель приготовления для оптимизации расписания этапов приготовления и… Просмотр через Publisher
jstage.jst.go.jp
Модель планирования блюд для традиционных китайских ресторанов на основе гибридных алгоритмов принятия решений по множеству критериев и двухуровневой структуры очередей
Модель планирования блюд для традиционных китайских ресторанов на основе Предлагаются гибридные алгоритмы принятия решений по нескольким критериям (MCDM) и двухуровневая структура очередей (DLQS), которые могут помочь в автоматизации планирования блюд и повысить общую удовлетворенность клиентов.
с показателем 1-10 из 17 ссылок
Сорт Byrelevancemost, под влиянием Papercercess,
Алгоритм планирования кулинарного шага для одновременного приготовления нескольких блюд
- Y. Matsushima, N. Funabiki, T. Nakanishi, Kanabeabeabeabeabeabeabeabeabeabeabeabeabeabeabeabeabeabeabeabeabeabeabeabeabeabeabeabeabe
- Y. Matsushima, N. Funabiki, T. Nakanishi, Kanabeabeabeabeabeabeabe.
Информатика
- 2012
В этой главе предлагается модель приготовления для точной оценки времени приготовления в различных условиях, включая планировку кухни и количество поваров, а также алгоритм планирования этапов приготовления для одновременного приготовления нескольких блюд. в соответствии с ограничением времени приготовления.
Cooking navi: помощник для ежедневного приготовления пищи на кухне
- R. Hamada, Jun Okabe, I. Ide, S. Satoh, S. Sakai, Hidehiko Tanaka
Информатика
МУЛЬТИМЕДИА '05
34
4
По результатам предварительного эксперимента, все пользователи, от новичка до опытного повара, могли одновременно готовить два блюда, получая при этом большое удовольствие от приготовления, показывает эффективность предлагаемой мультимедийной навигации.
Извлечение пищевых предпочтений пользователя для персонализированных рекомендаций по рецепту приготовления
- Маюми Уэда, Мари Такахата, Шинсуке Накадзима
Информатика
- 2011
предпочтения, и использует его/ее просмотр рецептов и историю приготовления для извлечения предпочтений пользователя.
Структурный анализ этапов приготовления пищи на японском языке
- Р. Хамада, И. Иде, С. Сакаи, Хидехико Танака
Информатика
IRAL '00
- 2000
предметный словарь статистическими методами, а также предложен метод структурного анализа с использованием словаря.
Рекомендации по еде: рассуждения о рецептах и ингредиентах
- Дж. Фрейн, С. Берковски
Информатика
UMAP
- 2010
Первый шаг к пониманию применимости рекомендательных методов в области пищевых продуктов и диет.
понижение рейтинга рецепта до рейтинга ингредиентов в целом дает наилучшие результаты.Мультимедийная интеграция для индексирования кулинарных видео
- Р. Хамада, Коичи Миура, И. Иде, С. Сато, С. Сакаи, Хидехико Танака
Информатика
PCM
- 2004
Предлагается система интеграции, которая выполняет семантическое сегментирование видео и текста и связывает их вместе, и благодаря этому методу станут возможными многие приложения, такие как программное обеспечение для навигации по кулинарии. .
Справочник по проектированию компиляторов: оптимизация и генерация машинного кода
Анализ времени выполнения и энергопотребления в наихудшем случае Т. Митра, А. Ройчаудхури Статический анализ программ для обеспечения безопасности К. Срикант, К. Вардхан Статистические методы и методы машинного обучения в разработке компиляторов К , Системы типа Васвани: достижения и приложения.
Итерационные компьютерные алгоритмы с приложениями в технике - решение задач комбинаторной оптимизации
- С. Саит, Х. Юссеф
Информатика
- 1999
Для каждой процедуры алгоритма авторы представляют параметр алгоритма критерии выбора, анализ свойств сходимости и распараллеливание. Есть также несколько реальных примеров…
Алгоритм преобразования веб-рецептов для планирования шагов приготовления
- Zhang Yijia, Funabiki Nobuo, Nakanishi Toru
Engineering
- 2014
An Android Application of Cooking Guidance Function in Homemade Cooking Assistance System
- Okada Tomoya, Matsushima Yukiko, Funabiki Nobuo, Nakanishi Toru, Watanabe Kan
Engineering
- 2013
Что такое алгоритм и что он означает для успеха вашего бизнеса?
Если вы когда-нибудь занимались SEO, вы слышали термин «алгоритм». В то время как многие владельцы веб-сайтов тратят бесчисленные часы, пытаясь занять высокие позиции в поисковых системах, большинство из них понятия не имеют, что такое алгоритм на самом деле, что он делает и как он влияет на их рейтинг.
Алгоритм — это пошаговая процедура, используемая для вычислений. Он используется для вычислений, обработки данных и для автоматизированных рассуждений. Набор правил создан для точного определения последовательности операций.
По сути, все, что вы хотите, чтобы компьютер делал, должна быть написана компьютерная программа. При написании компьютерной программы вы шаг за шагом говорите компьютеру, что вы хотите, чтобы он делал. Алгоритм — это уникальный процесс достижения конечной цели, и каждый алгоритм может предлагать разные методы, но каждый из них приводит к одному и тому же конечному выводу.
Давайте рассмотрим пример с использованием алгоритмов «реального мира» вместо компьютерных:
У вас званый обед, и вам нужно, чтобы ваш супруг приготовил ужин, вот три разных алгоритма (инструкции ) чтобы дать супругу, которые предлагают разные методы, но тот же конечный результат.
Домашняя еда Алгоритм:
- Сходить в магазин и купить продукты
- Сходить домой и приготовить еду
- Поужинайте на столе к 18:00.
Алгоритм на вынос:
- Позвонить в любимый ресторан и заказать еду
- Забрать еду и принести домой
- Поужинать на столе до 18:00.
Алгоритм доставки:
- Позвонить в любимый ресторан
- Принять доставку
- Поужинать на столе к 18:00.
Каждый из этих шагов предлагает один и тот же результат — ужин на столе к 18:00, но каждый из них предлагает совершенно разные шаги для достижения этой цели. Алгоритм поисковой системы работает одинаково, хотя каждая поисковая система может предлагать разные методы; все они работают для достижения одной и той же цели.
Каждый алгоритм имеет свои преимущества и недостатки, и поисковые системы находятся в постоянном поиске идеальной комбинации для достижения наилучших результатов. Это где вы приходите, ваш бизнес и ваш успех в Интернете.
Владельцам онлайн-бизнеса необходимо понимать алгоритмы поисковых систем, чтобы должным образом оптимизировать свой веб-сайт для получения наивысшего рейтинга.
Все это может показаться немного громоздким, но на самом деле все довольно просто.Что это значит для успеха вашего бизнеса?
Алгоритм и то, как его используют поисковые системы, имеют решающее значение для успеха вашего бизнеса. Чтобы занять высокое место в результатах поиска, ваша страница должна быть оптимизирована на основе методов сортировки поисковых систем.
В прошлом пользователи вводили ключевое слово или ключевую фразу в поисковую систему, и Google сортировал информацию в своей обширной базе данных, чтобы найти сайты, соответствующие этим словам. Сегодня вы можете ввести одни и те же ключевые слова в поисковую систему, но вы можете получить совершенно разные результаты.
Люди больше не просто вводят ключевые слова в поисковую систему, они задают вопросы. Google использовал алгоритм Hummingbird, чтобы ответить на эти вопросы. Таким образом, алгоритм больше не сортирует сайты по ключевому слову в соответствии с поиском пользователя, а по намерению контента ответить на вопрос пользователя.
Чем больше Google понимает, чего пользователь хочет от своего запроса, тем эффективнее он выдает правильные результаты. Таким образом, вы, возможно, заметили некоторые реальные изменения в Google, когда вы вводите поисковый запрос, и вы можете ожидать гораздо больше изменений в том, как отображаются результаты поиска, поскольку Google узнает все больше и больше о том, как пользователи действительно ищут информацию.Hummingbird хочет понять контекст вашего поиска, чтобы найти для вас наилучшие результаты. Итак, если вы спросите Google «какой отель в Тампе лучший?» Google также может вернуться с вопросами, такими как «вы имеете в виду лучшую цену, рейтинг или ближайший к вашему местоположению сейчас?» Это делается для того, чтобы полностью понять контекст вашего вопроса и принести вам наилучшие возможные результаты.
Веб-мастера должны убедиться, что их контент предлагает ответ на вопрос, заданный пользователем. Это означает отойти от ключевых слов и начать писать в соответствии с намерениями пользователя. Google усердно работает над тем, чтобы точно знать, чего хотят их пользователи, и предоставлять им только это, поэтому веб-мастерам нужно работать так же усердно, чтобы не отставать.Большое изменение
За последние несколько лет Google предложил множество обновлений, и осенью 2013 года алгоритм Hummingbird был представлен как одно из крупнейших изменений десятилетия. Другие обновления, такие как обновления Panda и Penguin, только модифицировали существующие алгоритмы поиска и затронули примерно 2-5% всех поисковых запросов. Hummingbird сильно повлиял на то, как поисковая система обрабатывала запросы, и, по оценкам, затронул почти 90% всех поисковых запросов.
Алгоритм Hummingbird был разработан для работы с более разговорным тоном, поэтому предлагает лучший результат для пользователя.
В прошлом пользователи вводили ключевое слово или ключевую фразу в поисковую систему, и Google сортировал информацию в своей обширной базе данных, чтобы найти сайты, соответствующие этим словам. Сегодня вы можете ввести одни и те же ключевые слова в поисковую систему, но вы можете получить совершенно разные результаты.Люди больше не просто вводят ключевые слова в поисковую систему, они задают вопросы. Google использовал алгоритм Hummingbird, чтобы ответить на эти вопросы.
Hummingbird хочет понять контекст вашего поиска, чтобы найти для вас наилучшие результаты. Итак, если вы спросите Google «какой отель в Тампе лучший?» Google также может вернуться с вопросами, такими как «вы имеете в виду лучшую цену, рейтинг или ближайший к вашему местоположению сейчас?» Это делается для того, чтобы полностью понять контекст вашего вопроса и принести вам наилучшие возможные результаты.
Изменения стратегии SEO
Поскольку люди изменили способ поиска, а Google изменил способ предоставления результатов, вам необходимо изменить свою стратегию SEO, чтобы вас заметили. Есть несколько вещей, которыми должен заниматься SEO-специалист, но в верхней части списка находится контент.
Включите вопросы в свой контент: Вместо того, чтобы тратить время на поиск ключевых слов, сосредоточьтесь больше на исследованиях рынка. Какие вопросы задает ваша целевая аудитория? И что еще более важно, как вы на них отвечаете?
Если содержание вашей страницы написано плохо, нет необходимости возвращаться и переписывать каждое слово, чтобы включить вопросы в работу. Вместо этого добавьте больше контента на страницу, чтобы ответить на вопросы, которые задает ваша аудитория. Если контент на вашей странице работает, нет необходимости его менять, просто добавьте к нему.
Вы можете отвечать на любое количество вопросов на каждой странице, нет необходимости в реализации правила «одна страница на вопрос». Пока Google может разобраться в вашем контенте и найти полный ответ на каждый вопрос на странице, все будет в порядке.
Создайте контент на своем сайте, чтобы сделать его достойным просмотра. Поскольку на многие вопросы поисковые системы отвечают непосредственно на боковой панели, если ваш сайт не предлагает более подробных и информативных ответов, вы можете никогда не увидеть трафик.